c1731983263ed0b509a6fbf296ad670603c4f238
PostgreSQL.md
| ... | ... | @@ -1,150 +1,761 @@ |
| 1 | -## PostgreSQL学习 |
|
| 1 | +# PostgreSQL 参考手册 |
|
| 2 | 2 | |
| 3 | -PostgreSQL版本:16.6 |
|
| 3 | +**PostgreSQL 版本:** 16.6 |
|
| 4 | 4 | |
| 5 | -下载地址: https://www.enterprisedb.com/downloads/postgres-postgresql-downloads |
|
| 5 | +**下载地址:** [Open-Source, Enterprise Postgres Database Management](https://www.enterprisedb.com/downloads/postgres-postgresql-downloads) |
|
| 6 | 6 | |
| 7 | -## 第 1 节. PG本地和Docker安装步骤 |
|
| 7 | +------ |
|
| 8 | + |
|
| 9 | +## 第 1 节. PostgreSQL 本地和 Docker 安装步骤 |
|
| 8 | 10 | |
| 9 | -### 一、本地安装PostgreSQL |
|
| 11 | +### 1. 本地安装 PG |
|
| 10 | 12 | |
| 11 | 13 | 以下是在本地 Windows 系统上安装 PostgreSQL 16.6 的流程: |
| 12 | 14 | |
| 13 | -#### 1. 下载安装包 |
|
| 15 | +1. **下载安装包** |
|
| 16 | + |
|
| 17 | + - 访问 [PostgreSQL 官方下载页面](https://www.postgresql.org/download/windows/) |
|
| 18 | + - 选择适合您系统的安装包 |
|
| 19 | + |
|
| 20 | +2. **运行安装程序** |
|
| 21 | + |
|
| 22 | + - 双击下载的安装程序文件,启动安装向导 |
|
| 23 | + - 在安装向导中,选择安装组件,包括 `PostgreSQL Server`、`pgAdmin 4` 和 `Command Line Tools` 等 |
|
| 24 | + |
|
| 25 | +3. **配置安装选项** |
|
| 26 | + |
|
| 27 | + - **选择安装目录**:默认安装目录为 `C:\Program Files\PostgreSQL\16`,可根据需要更改 |
|
| 28 | + - **设置数据目录**:默认数据目录为 `C:\Program Files\PostgreSQL\16\data`,可根据需要更改 |
|
| 29 | + - **设置超级用户密码**:输入并确认超级用户 `postgres` 的密码 |
|
| 30 | + - **设置端口号**:默认端口号为 `5432`,可根据需要更改 |
|
| 31 | + - **配置高级选项**:如需,可配置其他高级选项,如 `locale` 和 `encoding` 等 |
|
| 32 | + |
|
| 33 | +4. **完成安装** |
|
| 34 | + |
|
| 35 | + - 点击 `Install` 按钮开始安装 |
|
| 36 | + - 安装完成后,可选择是否启动 `Stack Builder` 来安装其他工具和驱动程序 |
|
| 37 | + |
|
| 38 | +5. **验证安装** |
|
| 39 | + |
|
| 40 | + - 打开 `Dbeaver`,连接到本地服务器,数据库: `postgres`,默认端口: `5432`,输入超级用户 `postgres` 的密码,验证连接是否成功 |
|
| 41 | + - 打开命令行工具,输入 `psql -U postgres -h localhost -p 5432`,验证是否可以成功登录到数据库 |
|
| 42 | + - PostgreSQL 默认的数据库名字是 `postgres`,默认的模式 `schema` 是: `public`,pg 的模式相当于 MySQL 的数据库,可以创建不同的模式 |
|
| 43 | + |
|
| 44 | +6. **DBCP 配置** |
|
| 45 | + |
|
| 46 | + ```properties |
|
| 47 | + ########postgresql######## |
|
| 48 | + driverClassName=org.postgresql.Driver |
|
| 49 | + url=jdbc:postgresql://localhost:5432/postgres?currentSchema=public&encoding=UTF-8&timezone=UTC |
|
| 50 | + username=postgres |
|
| 51 | + password=passw0rd |
|
| 52 | + ``` |
|
| 53 | + |
|
| 54 | +**参考资料** |
|
| 55 | + |
|
| 56 | +- [PostgreSQL 官方文档](https://www.postgresql.org/docs/) |
|
| 57 | +- [PostgreSQL 16 在 Windows 下安装](https://www.cnblogs.com/lwx11111/p/18375300) |
|
| 58 | +- [Windows 10 上安装 PostgreSQL 16](https://blog.csdn.net/fengbingchun/article/details/141750748) |
|
| 59 | +- [PostgreSQL 在 Windows 上的安装与配置](https://geek-docs.com/postgresql/postgresql-questions/218_tk_1704601434.html) |
|
| 60 | + |
|
| 61 | +### 2. Docker 安装 PG |
|
| 62 | + |
|
| 63 | +以下是在 `120` 机器上,使用 Docker 安装 PostgreSQL 16.6 的流程: |
|
| 64 | + |
|
| 65 | +1. **拉取镜像** |
|
| 66 | + |
|
| 67 | + 从 Docker Hub 上拉取 PostgreSQL 16.6 的镜像: |
|
| 68 | + |
|
| 69 | + ```bash |
|
| 70 | + docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/postgres:16.6-alpine3.21 |
|
| 71 | + docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/postgres:16.6-alpine3.21 docker.io/postgres:16.6 |
|
| 72 | + ``` |
|
| 73 | + |
|
| 74 | +2. **创建并运行 PostgreSQL 容器** |
|
| 75 | + |
|
| 76 | + 使用以下命令创建并运行一个 PostgreSQL 容器,并配置数据持久化: |
|
| 77 | + |
|
| 78 | + ```bash |
|
| 79 | + docker run --name postgres16 -e POSTGRES_PASSWORD=passw0rd -p 5432:5432 -v /opt/postgresql/data:/var/lib/postgresql/data -d docker.io/postgres:16.6 |
|
| 80 | + ``` |
|
| 81 | + |
|
| 82 | + - `--name postgres16`:指定容器名称为 `postgres16` |
|
| 83 | + - `-e POSTGRES_PASSWORD=mysecretpassword`:设置 PostgreSQL 的超级用户密码 |
|
| 84 | + - `-p 5432:5432`:将容器的 5432 端口映射到主机的 5432 端口 |
|
| 85 | + - `-v /opt/postgresql/data:/var/lib/postgresql/data`:将主机的目录(`/opt/postgresql/data`)挂载到容器的数据目录(`/var/lib/postgresql/data`),以实现数据持久化 |
|
| 86 | + |
|
| 87 | +3. **进入容器** |
|
| 88 | + |
|
| 89 | + 如果需要进入容器内部,可以使用以下命令: |
|
| 90 | + |
|
| 91 | + ```bash |
|
| 92 | + docker exec -it postgres16 bash |
|
| 93 | + ``` |
|
| 94 | + |
|
| 95 | +4. **连接到数据库** |
|
| 96 | + |
|
| 97 | + 在容器内部或宿主机上,可以使用 `psql` 命令连接到数据库: |
|
| 98 | + |
|
| 99 | + ```bash |
|
| 100 | + psql -U postgres -h localhost -p 5432 |
|
| 101 | + ``` |
|
| 102 | + |
|
| 103 | + - `-U postgres`:指定用户名为 `postgres` |
|
| 104 | + - `-h localhost`:指定主机名为 `localhost` |
|
| 105 | + - `-p 5432`:指定端口号为 `5432` |
|
| 106 | + |
|
| 107 | +5. **DBCP 配置** |
|
| 108 | + |
|
| 109 | + 已经在 `192.168.184.120` 安装了 PG,测试可以直接使用。PG 默认的模式是:`public`,可以通过设置 `currentSchema` 切换模式。 |
|
| 110 | + |
|
| 111 | + ```properties |
|
| 112 | + ########postgresql######## |
|
| 113 | + driverClassName=org.postgresql.Driver |
|
| 114 | + url=jdbc:postgresql://192.168.184.120:5432/postgres?currentSchema=public&encoding=UTF-8&timezone=UTC |
|
| 115 | + username=postgres |
|
| 116 | + password=passw0rd |
|
| 117 | + ``` |
|
| 118 | + |
|
| 119 | +**参考资料** |
|
| 120 | + |
|
| 121 | +- [Docker 安装 PostgreSQL 16.6](https://developer.baidu.com/article/detail.html?id=2812489) |
|
| 122 | +- [Docker+PostgreSQL 数据库](https://blog.csdn.net/shankezh/article/details/143241252) |
|
| 123 | +- [Docker 容器化部署 PostgreSQL](https://www.jianshu.com/p/c2f6759f3e75) |
|
| 124 | + |
|
| 125 | +------ |
|
| 126 | + |
|
| 127 | +## 第 2 节. PostgreSQL 特性 |
|
| 128 | + |
|
| 129 | +### 2.1 Boolean 值问题 |
|
| 130 | + |
|
| 131 | +PostgreSQL 支持 `boolean` 类型,但我们引擎是使用 `char(1)` 代替 `boolean`。插入到数据的时候我们插入 `char(1)`,查询的时候返回 `boolean` 值。 |
|
| 132 | + |
|
| 133 | +```sql |
|
| 134 | +CREATE TABLE example ( |
|
| 135 | + is_active CHAR(1) |
|
| 136 | +); |
|
| 137 | +``` |
|
| 138 | + |
|
| 139 | + |
|
| 140 | + |
|
| 141 | +### 2.2 索引问题 |
|
| 142 | + |
|
| 143 | +在 PostgreSQL 里,索引名称的最大长度受标识符最大长度限制,官方规定标识符最大长度为 63 字节。若标识符(如表名、列名、索引名等)长度超 63 字节,会自动截断并发出警告。 |
|
| 144 | + |
|
| 145 | +#### 1. PostgreSQL 索引命名规则与实践 |
|
| 146 | + |
|
| 147 | +1. **基本规则** |
|
| 148 | + |
|
| 149 | + - **长度**:索引名最长 63 字节,超量自动截断并告警 |
|
| 150 | + - **字符集**:可含字母、数字、下划线和特殊字符,建议只用前三者 |
|
| 151 | + - **大小写**:默认转小写存储,用双引号包裹可保留大小写 |
|
| 152 | + - **唯一性**:在同一个 `schema` 中,索引名称必须唯一,创建同名索引会引发错误 |
|
| 153 | + |
|
| 154 | +2. **命名限制** |
|
| 155 | + |
|
| 156 | + - **长度**:长度超过 63 字节会被截断。 |
|
| 157 | + |
|
| 158 | + ```sql |
|
| 159 | + CREATE INDEX this_is_a_very_long_index_name_that_exceeds_the_maximum_length_of_sixty_three_bytes ON my_table(my_column); |
|
| 160 | + -- PostgreSQL 会将其截断为 |
|
| 161 | + this_is_a_very_long_index_name_that_exceeds_the_maximum_length_of_sixty_three |
|
| 162 | + ``` |
|
| 163 | + |
|
| 164 | + - **大小写**:默认转小写,用 `"MyIndex"` 可保留 |
|
| 165 | + |
|
| 166 | + - **特殊字符**:可含特殊字符,但可能有兼容性问题,如 `"my_index$1"` |
|
| 167 | + |
|
| 168 | + - **唯一性**:同一 `schema` 内重名报错,如 `CREATE INDEX my_index ON my_table(my_column);` 后再创建同名索引会冲突。 |
|
| 169 | + |
|
| 170 | + ```sql |
|
| 171 | + CREATE INDEX my_index ON my_table(my_column); |
|
| 172 | + CREATE INDEX my_index ON my_table(another_column); -- 错误:索引名称冲突 |
|
| 173 | + ``` |
|
| 174 | + |
|
| 175 | +3. **最佳实践** |
|
| 176 | + |
|
| 177 | + - **索引名称应反映其用途**:如 `idx_table_column` 表示普通索引,`uk_table_column` 表示唯一约束索引。例如: |
|
| 14 | 178 | |
| 15 | -- 访问 PostgreSQL 官方下载页面:[PostgreSQL 下载](https://www.postgresql.org/download/windows/) |
|
| 16 | -- 选择适合您系统的安装包(建议选择 `PostgreSQL Server` 和 `pgAdmin 4`)。 |
|
| 179 | + - `idx_table_column`:表示在 `table` 表的 `column` 列上创建的索引 |
|
| 180 | + - `uk_table_column`:表示在 `table` 表的 `column` 列上创建的唯一约束索引 |
|
| 17 | 181 | |
| 18 | -#### 2. 运行安装程序 |
|
| 182 | + - **避保留字**:不用 `SELECT`、`INSERT` 等保留字命名 |
|
| 19 | 183 | |
| 20 | -- 双击下载的安装程序文件,启动安装向导。 |
|
| 21 | -- 在安装向导中,选择安装组件,包括 `PostgreSQL Server`、`pgAdmin 4` 和 `Command Line Tools` 等。 |
|
| 184 | + - **使用一致的命名规则**: |
|
| 22 | 185 | |
| 23 | -#### 3. 配置安装选项 |
|
| 186 | + - 前缀:使用 `idx_` 表示普通索引,`uk_` 表示唯一索引,`pk_` 表示主键索引 |
|
| 187 | + - 表名和列名:在索引名称中包含表名和列名 |
|
| 24 | 188 | |
| 25 | -- **选择安装目录**:默认安装目录为 `C:\Program Files\PostgreSQL\16`,您可以根据需要更改。 |
|
| 26 | -- **设置数据目录**:默认数据目录为 `C:\Program Files\PostgreSQL\16\data`,您可以根据需要更改。 |
|
| 27 | -- **设置超级用户密码**:输入并确认超级用户 `postgres` 的密码。 |
|
| 28 | -- **设置端口号**:默认端口号为 `5432`,您可以根据需要更改。 |
|
| 29 | -- **配置高级选项**:如需要,可以配置其他高级选项,如 `locale` 和 `encoding` 等。 |
|
| 189 | + 例如: |
|
| 30 | 190 | |
| 31 | -#### 4. 完成安装 |
|
| 191 | + ```sql |
|
| 192 | + CREATE INDEX idx_users_email ON users(email); |
|
| 193 | + CREATE UNIQUE INDEX uk_users_username ON users(username); |
|
| 194 | + ``` |
|
| 32 | 195 | |
| 33 | -- 点击 `Install` 按钮开始安装。 |
|
| 34 | -- 安装完成后,您可以选择是否启动 `Stack Builder` 来安装其他工具和驱动程序。 |
|
| 196 | + - **长度限制**:避免超过 63 字节 |
|
| 35 | 197 | |
| 36 | -#### 5. 验证安装 |
|
| 198 | +4. **修改索引名** |
|
| 37 | 199 | |
| 38 | -- 打开 `Dbeaver`,连接到本地服务器,数据库:`postgres` ,默认端口:`5432`, 输入超级用户 `postgres` 的密码,验证连接是否成功。 |
|
| 39 | -- 打开命令行工具,输入 `psql -U postgres -h localhost -p 5432`,验证是否可以成功登录到数据库。 |
|
| 40 | -- PostgreSQL 默认的数据库名字是`postgres`, 默认的模式`schema`是:`public`,pg的模式相当于MySQL的数据库,可以创建不同的模式。 |
|
| 200 | + 使用 `ALTER INDEX old_index_name RENAME TO new_index_name;` 修改 |
|
| 41 | 201 | |
| 42 | -#### 6. DBCP配置 |
|
| 202 | +5. **查看索引名** |
|
| 43 | 203 | |
| 204 | + 用以下 SQL 查询: |
|
| 205 | + |
|
| 206 | + ```sql |
|
| 207 | + SELECT schemaname, tablename, indexname |
|
| 208 | + FROM pg_indexes |
|
| 209 | + WHERE schemaname NOT LIKE 'pg_%' |
|
| 210 | + ORDER BY schemaname, tablename, indexname; |
|
| 211 | + ``` |
|
| 212 | + |
|
| 213 | + |
|
| 214 | + |
|
| 215 | +### 2.3 PG 支持 Transactional DDL |
|
| 216 | + |
|
| 217 | +#### 1. 参考资料 |
|
| 218 | + |
|
| 219 | +- [PostgreSQL 中的事务性 DDL: 数据库对比](https://www.rockdata.net/zh-cn/blog/transactional-ddl/) |
|
| 220 | +- [Transactional DDL in PostgreSQL: A Competitive Analysis](https://wiki.postgresql.org/wiki/Transactional_DDL_in_PostgreSQL:_A_Competitive_Analysis) |
|
| 221 | + |
|
| 222 | +#### 2. 什么是 Transactional DDL? |
|
| 223 | + |
|
| 224 | +Transactional(事务)在关系型数据库是指一组 SQL 语句,要么提交,要么全部回滚。事务中包含的语句通常是 DML 语句,如 `INSERT`、`UPDATE`、`DELETE` 等。但对于 DDL 语句呢?是否可以在事务中包含诸如 `CREATE`、`ALTER`、`DROP` 等 DDL 命令? |
|
| 225 | + |
|
| 226 | +所谓 Transactional DDL 就是我们可以把 DDL 放到事务中,做到事务中的 DDL 语句要么全部提交,要么全部回滚。 |
|
| 227 | + |
|
| 228 | +**看个 PG 的例子** |
|
| 229 | + |
|
| 230 | +```sql |
|
| 231 | +postgres=# begin; |
|
| 232 | +BEGIN |
|
| 233 | +postgres=*# create table a_test(id int); |
|
| 234 | +CREATE TABLE |
|
| 235 | +postgres=*# insert into a_test values(1); |
|
| 236 | +INSERT 0 1 |
|
| 237 | +postgres=*# rollback; |
|
| 238 | +ROLLBACK |
|
| 239 | +postgres=# select * from a_test; |
|
| 240 | +ERROR: relation "a_test" does not exist |
|
| 241 | +LINE 1: select * from a_test; |
|
| 242 | + ^ |
|
| 243 | +postgres=# |
|
| 44 | 244 | ``` |
| 45 | -########postgresql######## |
|
| 46 | -driverClassName=org.postgresql.Driver |
|
| 47 | -url=jdbc:postgresql://localhost:5432/postgres?currentSchema=public&encoding=UTF-8&timezone=UTC |
|
| 48 | -username=postgres |
|
| 49 | -password=passw0rd |
|
| 50 | 245 | |
| 246 | +可见,在 PostgreSQL 中,是支持 Transactional DDL 的,在上例中,`create table` 语句被回滚掉了。 |
|
| 247 | + |
|
| 248 | +并不是所有数据库都支持 Transactional DDL,比如 MySQL。 |
|
| 249 | + |
|
| 250 | +**看个 MySQL 的例子** |
|
| 251 | + |
|
| 252 | +```sql |
|
| 253 | +mysql> begin; |
|
| 254 | +Query OK, 0 rows affected (0.00 sec) |
|
| 255 | + |
|
| 256 | +mysql> create table a_test (id int); |
|
| 257 | +Query OK, 0 rows affected (0.04 sec) |
|
| 258 | + |
|
| 259 | +mysql> insert into a_test values(1); |
|
| 260 | +Query OK, 1 row affected (0.01 sec) |
|
| 261 | + |
|
| 262 | +mysql> rollback; |
|
| 263 | +Query OK, 0 rows affected (0.00 sec) |
|
| 264 | + |
|
| 265 | +mysql> select * from a_test; |
|
| 266 | ++------+ |
|
| 267 | +| id | |
|
| 268 | ++------+ |
|
| 269 | +| 1 | |
|
| 270 | ++------+ |
|
| 271 | +1 row in set (0.00 sec) |
|
| 51 | 272 | ``` |
| 52 | 273 | |
| 53 | -#### 参考资料 |
|
| 274 | +可以看到 MySQL 这个例子里,不仅 `create` 语句没有回滚掉,`insert` 语句也没有回滚掉。这是因为:在 MySQL 中,当执行 DDL 语句时,会隐式地将当前会话的事务进行一次提交操作。所以我们应该严格地将 DDL 和 DML 完全分开,不能混合在一起执行。 |
|
| 54 | 275 | |
| 55 | -- [PostgreSQL 官方文档](https://www.postgresql.org/docs/) |
|
| 276 | +**一些特例** |
|
| 56 | 277 | |
| 57 | -- [PostgreSQL 16 在 Windows 下安装](https://www.cnblogs.com/lwx11111/p/18375300) |
|
| 278 | +需要注意的是在 PG 中并不是所有的 DDL 都支持 Transactional DDL。比如 `CREATE INDEX CONCURRENTLY`、`CREATE DATABASE`、`CREATE TABLESPACE` 等等。 |
|
| 58 | 279 | |
| 59 | -- [Windows 10 上安装 PostgreSQL 16](https://blog.csdn.net/fengbingchun/article/details/141750748) |
|
| 280 | +```sql |
|
| 281 | +postgres=# begin; |
|
| 282 | +BEGIN |
|
| 283 | +postgres=*# CREATE INDEX CONCURRENTLY idx_id ON a_test (id); |
|
| 284 | +ERROR: CREATE INDEX CONCURRENTLY cannot run inside a transaction block |
|
| 285 | +``` |
|
| 60 | 286 | |
| 61 | -- [PostgreSQL 在 Windows 上的安装与配置](https://geek-docs.com/postgresql/postgresql-questions/218_tk_1704601434.html) |
|
| 287 | +#### 3. Transactional DDL 的好处 |
|
| 62 | 288 | |
| 63 | - |
|
| 289 | +在进行一些模式升级等复杂工作时,可以利用此功能保护数据库。我们可以将所有更改都放入事务块中,确保它们都以原子方式应用,或者根本不应用。这大大降低了数据库因模式更改中的输入错误或其他此类错误而损坏数据库的可能性。 |
|
| 64 | 290 | |
| 65 | -### 二、Docker安装PostgreSQL |
|
| 291 | +#### 4. PG 中的事务性 DDL: 数据库对比 |
|
| 66 | 292 | |
| 67 | -以下是在192.168.184.120 机器上,使用 Docker 安装 PostgreSQL 16.6 的流程: |
|
| 293 | +**事务性 DDL** |
|
| 68 | 294 | |
| 69 | -#### 1. 拉取镜像 |
|
| 295 | +与一些商业数据库一样,PostgreSQL 中有一个比较高级的功能,它能够通过其 [预写式日志](https://www.rockdata.net/zh-cn/docs/14/wal.html) 的设计执行事务性 DDL。该设计支持回退 DDL 产生的重大更改,例如表创建。您无法恢复添加和删除数据库或表空间的操作,但所有其他的对象操作都是可逆的。 |
|
| 70 | 296 | |
| 71 | -从 Docker Hub 上拉取 PostgreSQL 16.6 的镜像: |
|
| 297 | +**PostgreSQL** |
|
| 72 | 298 | |
| 73 | -bash复制 |
|
| 299 | +下面是一个示例,显示了 PostgreSQL 的设计在这方面的处理能力: |
|
| 74 | 300 | |
| 75 | -```bash |
|
| 76 | -docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/postgres:16.6-alpine3.21 |
|
| 77 | -docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/postgres:16.6-alpine3.21 docker.io/postgres:16.6 |
|
| 301 | +```sql |
|
| 302 | +DROP TABLE IF EXISTS foo; |
|
| 303 | +NOTICE: table "foo" does not exist |
|
| 304 | + |
|
| 305 | +BEGIN; |
|
| 306 | +CREATE TABLE foo (bar int); |
|
| 307 | +INSERT INTO foo VALUES (1); |
|
| 308 | +ROLLBACK; |
|
| 309 | + |
|
| 310 | +SELECT * FROM foo; |
|
| 311 | +ERROR: relation "foo" does not exist |
|
| 78 | 312 | ``` |
| 79 | 313 | |
| 80 | -#### 2. 创建并运行 PostgreSQL 容器 |
|
| 314 | +有经验的 PostgreSQL DBA 知道,在执行表结构升级等复杂工作时,可利用此功能来保护自己。如果你把所有这些变更都放到一个事务块中,你可以确保它们都以原子方式进行应用,或者完全不应用。这大大降低了数据库因架构变更中的拼写错误或其他此类错误而损坏的可能性,这在修改多个相关表时尤为重要,因为错误可能会破坏关系键。 |
|
| 315 | + |
|
| 316 | +**MySQL** |
|
| 317 | + |
|
| 318 | +如果您在使用 MySQL,则无法以这种方式撤消 DDL 和一些类似的更改。如果您使用的是 MyISAM 存储引擎,那它根本不支持事务。对于 InnoDB 存储引擎,服务端有一种 [隐式提交](https://dev.mysql.com/doc/refman/8.4/en/implicit-commit.html),即使关闭了正常的自动提交行为,DDL 命令也会导致当前事务发生隐式提交。 |
|
| 319 | + |
|
| 320 | +```sql |
|
| 321 | +set autocommit = 0; |
|
| 322 | + |
|
| 323 | +drop table foo; |
|
| 324 | + |
|
| 325 | +create table foo (bar int) engine=InnoDB; |
|
| 81 | 326 | |
| 82 | -使用以下命令创建并运行一个 PostgreSQL 容器,并配置数据持久化: |
|
| 327 | +insert into foo values (1); |
|
| 83 | 328 | |
| 84 | -```bash |
|
| 85 | -docker run --name postgres16 -e POSTGRES_PASSWORD=passw0rd -p 5432:5432 -v /opt/postgresql/data:/var/lib/postgresql/data -d docker.io/postgres:16.6 |
|
| 329 | +rollback; |
|
| 330 | + |
|
| 331 | +select * from foo; |
|
| 332 | +Empty set (0.00 sec) |
|
| 86 | 333 | ``` |
| 87 | 334 | |
| 88 | -- `--name postgres16`:指定容器名称为 `postgres16`。 |
|
| 89 | -- `-e POSTGRES_PASSWORD=mysecretpassword`:设置 PostgreSQL 的超级用户密码。 |
|
| 90 | -- `-p 5432:5432`:将容器的 5432 端口映射到主机的 5432 端口。 |
|
| 91 | -- `-v /opt/postgresql/data:/var/lib/postgresql/data`:将主机的目录(`/opt/postgresql/data`)挂载到容器的数据目录(`/var/lib/postgresql/data`),以实现数据持久化。 |
|
| 335 | +**Oracle** |
|
| 336 | + |
|
| 337 | +一个事务从第一个可执行的 SQL 语句开始。事务在提交或回滚时结束,无论是显式使用 `COMMIT` 或 `ROLLBACK` 语句,还是在发出 DDL 语句时隐式提交。 |
|
| 338 | + |
|
| 339 | +Oracle 数据库在以下情况下会发生隐式 `COMMIT`: |
|
| 340 | + |
|
| 341 | +- 在任何语法上有效的数据定义语言(DDL)的语句之前,即使该语句发生了错误 |
|
| 342 | +- 在任何没有发生错误执行完成的数据定义语言(DDL)语句之后 |
|
| 343 | + |
|
| 344 | +让我们在 Oracle 中创建一个表,并插入一行: |
|
| 345 | + |
|
| 346 | +```sql |
|
| 347 | +-- Create a table and insert a row |
|
| 348 | +CREATE TABLE states |
|
| 349 | +( |
|
| 350 | + abbr CHAR(2), |
|
| 351 | + name VARCHAR2(90) |
|
| 352 | +); |
|
| 353 | + |
|
| 354 | +-- Transaction will be in progress after this insert |
|
| 355 | +INSERT INTO states VALUES ('CA', 'California'); |
|
| 356 | +``` |
|
| 92 | 357 | |
| 93 | -#### 3. 进入容器 |
|
| 358 | +现在,让我们创建另一个表,并执行 `ROLLBACK` 操作: |
|
| 94 | 359 | |
| 95 | -如果需要进入容器内部,可以使用以下命令: |
|
| 360 | +```sql |
|
| 361 | +-- Create another table table and insert a row |
|
| 362 | +CREATE TABLE cities |
|
| 363 | +( |
|
| 364 | + name VARCHAR2(90), |
|
| 365 | + state CHAR(2) |
|
| 366 | +); |
|
| 96 | 367 | |
| 97 | -bash复制 |
|
| 368 | +INSERT INTO cities VALUES ('San Francisco', 'CA'); |
|
| 98 | 369 | |
| 99 | -```bash |
|
| 100 | -docker exec -it postgres16 bash |
|
| 370 | +ROLLBACK; |
|
| 101 | 371 | ``` |
| 102 | 372 | |
| 103 | -#### 5. 连接到数据库 |
|
| 373 | +您可以看到,即使在 `ROLLBACK` 之后,表 `states` 和表中的行仍然存在,因为 `CREATE TABLE cities` 语句提交了事务。 |
|
| 104 | 374 | |
| 105 | -在容器内部或宿主机上,可以使用 `psql` 命令连接到数据库: |
|
| 375 | +表 `cities` 也存在,但插入的行已回滚: |
|
| 106 | 376 | |
| 107 | -bash复制 |
|
| 377 | +```sql |
|
| 378 | +-- Table states exists and contains 1 row |
|
| 379 | +SELECT COUNT(*) FROM states; |
|
| 380 | +-- Result: 1 |
|
| 108 | 381 | |
| 109 | -```bash |
|
| 110 | -psql -U postgres -h localhost -p 5432 |
|
| 382 | +-- Table cities also exists, but the inserted row was rolled back |
|
| 383 | +SELECT COUNT(*) FROM cities; |
|
| 384 | +-- Result: 0 |
|
| 111 | 385 | ``` |
| 112 | 386 | |
| 113 | -- `-U postgres`:指定用户名为 `postgres`。 |
|
| 114 | -- `-h localhost`:指定主机名为 `localhost`。 |
|
| 115 | -- `-p 5432`:指定端口号为 `5432`。 |
|
| 116 | 387 | |
| 117 | -#### 6. DBCP配置 |
|
| 118 | 388 | |
| 119 | -已经在192.168.184.120安装了PG,测试可以直接使用。PG默认的模式是:public,可以通过设置`currentSchema`切换模式。 |
|
| 389 | +### 2.4 PG 数据类型转换规则 |
|
| 390 | + |
|
| 391 | +PostgreSQL 的自动类型转换规则是比较严格的,尤其是从字符串到其他类型的转换,通常需要显式指定 PostgreSQL 要求显式的数据类型转换。 |
|
| 120 | 392 | |
| 393 | +#### 1. 示例:数据类型转换错误 |
|
| 394 | + |
|
| 395 | +```sql |
|
| 396 | +INSERT INTO a_test (age) VALUES ('123'); -- 错误:字段 "age" 的类型为 integer, 但表达式的类型为 character varying |
|
| 121 | 397 | ``` |
| 122 | -########postgresql######## |
|
| 123 | -driverClassName=org.postgresql.Driver |
|
| 124 | -url=jdbc:postgresql://192.168.184.120:5432/postgres?currentSchema=public&encoding=UTF-8&timezone=UTC |
|
| 125 | -username=postgres |
|
| 126 | -password=passw0rd |
|
| 127 | 398 | |
| 399 | +#### 2. 解决方法 |
|
| 400 | + |
|
| 401 | +在插入或更新数据时,确保数据类型匹配,或使用显式类型转换: |
|
| 402 | + |
|
| 403 | +```sql |
|
| 404 | +INSERT INTO a_test (age) VALUES (CAST('123' AS INTEGER)); |
|
| 128 | 405 | ``` |
| 129 | 406 | |
| 407 | +#### 3. 自动类型转换(Implicit Casting) |
|
| 130 | 408 | |
| 409 | +PostgreSQL 会在某些情况下自动进行数据类型转换,以确保操作的正确性。这些情况主要是为了匹配操作符或函数的参数类型。 |
|
| 131 | 410 | |
| 132 | -### 参考资料 |
|
| 411 | +1. **字符串到数字的隐式转换(受限)**: |
|
| 133 | 412 | |
| 134 | -- [Docker 安装 PostgreSQL 16.6](https://developer.baidu.com/article/detail.html?id=2812489) |
|
| 135 | -- [Docker+PostgreSQL数据库](https://blog.csdn.net/shankezh/article/details/143241252) |
|
| 136 | -- [Docker 容器化部署 PostgreSQL](https://www.jianshu.com/p/c2f6759f3e75) |
|
| 413 | + - PostgreSQL 不会自动将字符串转换为数字类型(如 `integer` 或 `numeric`)。例如: |
|
| 137 | 414 | |
| 415 | + ```sql |
|
| 416 | + SELECT '123' + 456; -- 报错:类型不匹配 |
|
| 417 | + ``` |
|
| 138 | 418 | |
| 419 | + 如果要进行这种操作,必须显式转换类型。 |
|
| 139 | 420 | |
| 421 | +2. **字符串与字符串的连接**: |
|
| 140 | 422 | |
| 141 | -## PostgreSQL 基础教程 |
|
| 423 | + - 如果两个操作数都是字符串类型,可以自动进行连接操作: |
|
| 142 | 424 | |
| 143 | -https://www.rockdata.net/zh-cn/tutorial/toc/ |
|
| 425 | + ```sql |
|
| 426 | + SELECT 'Hello' || 'World'; -- 结果为 'HelloWorld' |
|
| 427 | + ``` |
|
| 144 | 428 | |
| 145 | -本 **PostgreSQL 教程**可帮助您快速了解 PostgreSQL。您将通过许多实际示例快速掌握 PostgreSQL,并将这些知识应用于使用 PostgreSQL 开发应用程序。 |
|
| 429 | +3. **字符串与其他类型的隐式转字符串**: |
|
| 430 | + |
|
| 431 | + - 如果一个操作符或函数期望一个字符串类型的参数,而提供的是一个非字符串类型,PostgreSQL 会尝试将其隐式转换为字符串: |
|
| 432 | + |
|
| 433 | + ```sql |
|
| 434 | + SELECT 42 || ' apples'; -- 结果为 '42 apples' |
|
| 435 | + ``` |
|
| 436 | + |
|
| 437 | +#### 4. 显式类型转换(Explicit Casting) |
|
| 438 | + |
|
| 439 | +显式类型转换是 PostgreSQL 中推荐的做法,用于明确地将数据从一种类型转换为另一种类型。以下是几种常用的显式类型转换方法: |
|
| 440 | + |
|
| 441 | +1. **使用 `CAST` 函数**: |
|
| 442 | + |
|
| 443 | + - `CAST` 是标准 SQL 提供的类型转换函数。例如: |
|
| 444 | + |
|
| 445 | + ```sql |
|
| 446 | + SELECT CAST('123' AS INTEGER); -- 结果为 123 |
|
| 447 | + ``` |
|
| 146 | 448 | |
| 449 | + 你也可以指定其他目标类型,如 `DOUBLE PRECISION`、`DATE` 等: |
|
| 147 | 450 | |
| 451 | + ```sql |
|
| 452 | + SELECT CAST('3.1415' AS NUMERIC(5,2)); -- 结果为 3.14 |
|
| 453 | + ``` |
|
| 454 | + |
|
| 455 | +2. **使用列定义语法**: |
|
| 456 | + |
|
| 457 | + - 使用列定义语法也可以进行类型转换。例如: |
|
| 458 | + |
|
| 459 | + ```sql |
|
| 460 | + SELECT '2024-01-01'::DATE; -- 结果为 2024-01-01 |
|
| 461 | + ``` |
|
| 462 | + |
|
| 463 | + 这种方法与 `CAST` 功能相同,但语法更简洁。 |
|
| 464 | + |
|
| 465 | +3. **使用 `::` 运算符**: |
|
| 466 | + |
|
| 467 | + - `::` 是 PostgreSQL 提供的快捷方式,用于类型转换。例如: |
|
| 468 | + |
|
| 469 | + ```sql |
|
| 470 | + SELECT '25'::integer; -- 结果为 25 |
|
| 471 | + ``` |
|
| 472 | + |
|
| 473 | +#### 5. 类型转换的注意事项 |
|
| 474 | + |
|
| 475 | +1. **避免非显式转换**: |
|
| 476 | + |
|
| 477 | + - 尽量避免依赖隐式类型转换,因为它可能导致意外的错误。例如: |
|
| 478 | + |
|
| 479 | + ```sql |
|
| 480 | + INSERT INTO users (age) VALUES ('25'); -- 报错,除非 `age` 是 `VARCHAR` 类型 |
|
| 481 | + ``` |
|
| 482 | + |
|
| 483 | + 如果 `age` 是 `BOOLEAN` 类型,而你尝试插入 `TRUE`,必须显式转换为布尔值: |
|
| 484 | + |
|
| 485 | + ```sql |
|
| 486 | + INSERT INTO users (age) VALUES (TRUE::BOOLEAN); |
|
| 487 | + ``` |
|
| 488 | + |
|
| 489 | +2. **处理文本与日期/时间**: |
|
| 490 | + |
|
| 491 | + - 当将字符串转换为日期或时间类型时,必须遵循正确的格式。例如: |
|
| 492 | + |
|
| 493 | + ```sql |
|
| 494 | + SELECT CAST('2023-10-05' AS DATE); -- 正确 |
|
| 495 | + SELECT CAST('10/05/2023' AS DATE); -- 抛出错误,因为格式不匹配 |
|
| 496 | + ``` |
|
| 497 | + |
|
| 498 | + 如果需要将日期以特定格式存储或解析,可以使用 `TO_DATE` 函数: |
|
| 499 | + |
|
| 500 | + ```sql |
|
| 501 | + SELECT TO_DATE('05-OCT-2023', 'DD-MON-YYYY'); -- 结果为 2023-10-05 |
|
| 502 | + ``` |
|
| 503 | + |
|
| 504 | +3. **数组类型的转换**: |
|
| 505 | + |
|
| 506 | + - 数组之间的类型转换通常比标量类型更复杂。例如,将 `{1,2,3}` 转换为 `int[]` 是可以直接的: |
|
| 507 | + |
|
| 508 | + ```sql |
|
| 509 | + SELECT '{1,2,3}'::int[]; -- 正确 |
|
| 510 | + ``` |
|
| 511 | + |
|
| 512 | + 但是,将字符串数组转换为其他类型数组可能需要额外的处理。 |
|
| 513 | + |
|
| 514 | +4. **类型转换失败**: |
|
| 515 | + |
|
| 516 | + - 如果转换无法完成,PostgreSQL 会抛出错误。例如: |
|
| 517 | + |
|
| 518 | + ```sql |
|
| 519 | + SELECT CAST('text' AS INTEGER); -- 抛出错误:invalid input syntax for type integer |
|
| 520 | + ``` |
|
| 521 | + |
|
| 522 | +#### 6. 示例 |
|
| 523 | + |
|
| 524 | +以下是一些常见的类型转换示例: |
|
| 525 | + |
|
| 526 | +1. **将字符串转换为整数**: |
|
| 527 | + |
|
| 528 | + ```sql |
|
| 529 | + SELECT CAST('42' AS INTEGER); -- 结果为 42 |
|
| 530 | + SELECT '42'::integer; -- 同上 |
|
| 531 | + ``` |
|
| 532 | + |
|
| 533 | +2. **将数字转换为字符串**: |
|
| 534 | + |
|
| 535 | + ```sql |
|
| 536 | + SELECT CAST(42 AS VARCHAR); -- 结果为 '42' |
|
| 537 | + ``` |
|
| 538 | + |
|
| 539 | +3. **将布尔值转换为整数(逻辑上不推荐,但支持)**: |
|
| 540 | + |
|
| 541 | + ```sql |
|
| 542 | + SELECT CAST(TRUE AS INTEGER); -- 结果为 1 |
|
| 543 | + SELECT CAST(FALSE AS INTEGER); -- 结果为 0 |
|
| 544 | + ``` |
|
| 545 | + |
|
| 546 | +4. **将字符串转换为布尔值**: |
|
| 547 | + |
|
| 548 | + ```sql |
|
| 549 | + SELECT CAST('t' AS BOOLEAN); -- 结果为 TRUE |
|
| 550 | + SELECT CAST('false' AS BOOLEAN); -- 结果为 FALSE |
|
| 551 | + ``` |
|
| 552 | + |
|
| 553 | + |
|
| 554 | + |
|
| 555 | +### 2.5 PostgreSQL 错误:`current transaction is aborted, commands ignored until end of transaction block` |
|
| 556 | + |
|
| 557 | +#### 1. 错误概述 |
|
| 558 | + |
|
| 559 | +当 PostgreSQL 事务中的某条 SQL 语句执行失败时,整个事务会进入 **中止状态**(Aborted)。所有后续的 SQL 命令都会被忽略,直到事务被回滚或关闭。此时任何后续操作都会触发以下错误:`current transaction is aborted, commands ignored until end of transaction block`。 |
|
| 560 | + |
|
| 561 | +**核心问题**:事务未正确终止(未提交或回滚),导致数据库连接处于不可用状态。 |
|
| 562 | + |
|
| 563 | +**错误信息**: |
|
| 564 | + |
|
| 565 | +```java |
|
| 566 | +caused by: org.postgresql.util.PSQLException: 错误: 当前事务被终止, 事务块结束之前的查询被忽略 |
|
| 567 | +current transaction is aborted, commands ignored until end of transaction block |
|
| 568 | +``` |
|
| 569 | + |
|
| 570 | +#### 2. 事务块中语句错误的回滚行为:数据库对比 |
|
| 571 | + |
|
| 572 | +**摘要**:在本文中,我们将学习事务块中语句错误的回滚行为,以及 PostgreSQL 和 Oracle 之间的区别。 |
|
| 573 | + |
|
| 574 | +**参考文章** |
|
| 575 | + |
|
| 576 | +- [PostgreSQL - ERROR: current transaction is aborted](https://www.rockdata.net/zh-cn/blog/rollback-on-statement-error/#postgresql---error-current-transaction-is-aborted) |
|
| 577 | +- [Oracle 语句级回滚](https://www.rockdata.net/zh-cn/blog/rollback-on-statement-error/#oracle-语句级回滚) |
|
| 578 | + |
|
| 579 | +通常,您制造的任何错误都会引发异常,并导致当前事务被标记为中止。这是理智和预期的行为,但如果它发生在您运行大型事务并输入了错误内容时,这可能会非常的烦人!此时,您唯一能做的就是回滚事务并丢弃所有工作。 |
|
| 580 | + |
|
| 581 | +当您在 PostgreSQL 中遇到错误时,事务是无法继续的。例如: |
|
| 582 | + |
|
| 583 | +```sql |
|
| 584 | +DROP TABLE IF EXISTS demo; |
|
| 585 | + |
|
| 586 | +START TRANSACTION; |
|
| 587 | +CREATE TABLE demo(n, t) AS SELECT 1 n, current_timestamp t; |
|
| 588 | +ALTER TABLE demo ADD UNIQUE(n); |
|
| 589 | + |
|
| 590 | +SELECT * FROM demo; |
|
| 591 | + n | t |
|
| 592 | +---+------------------------------- |
|
| 593 | + 1 | 2021-06-26 18:15:07.207671+08 |
|
| 594 | +(1 row) |
|
| 595 | + |
|
| 596 | +INSERT INTO demo VALUES (2, current_timestamp); |
|
| 597 | +SELECT * FROM demo; |
|
| 598 | + n | t |
|
| 599 | +---+------------------------------- |
|
| 600 | + 1 | 2021-06-26 18:15:07.207671+08 |
|
| 601 | + 2 | 2021-06-26 18:15:07.207671+08 |
|
| 602 | +(2 rows) |
|
| 603 | + |
|
| 604 | +INSERT INTO demo VALUES (1, current_timestamp); |
|
| 605 | +ERROR: duplicate key value violates unique constraint "demo_n_key" |
|
| 606 | +DETAIL: Key (n)=(1) already exists. |
|
| 607 | + |
|
| 608 | +SELECT * FROM demo; |
|
| 609 | +ERROR: current transaction is aborted, commands ignored until end of transaction block |
|
| 610 | + |
|
| 611 | +ROLLBACK; |
|
| 612 | + |
|
| 613 | +SELECT * FROM demo; |
|
| 614 | +ERROR: relation "demo" does not exist |
|
| 615 | +LINE 1: SELECT * FROM demo; |
|
| 616 | +``` |
|
| 617 | + |
|
| 618 | +在这里我们进行了回滚。但其实也可以提交来终止事务,但它无论如何都会回滚: |
|
| 619 | + |
|
| 620 | +```sql |
|
| 621 | +COMMIT; |
|
| 622 | + |
|
| 623 | +SELECT * FROM demo; |
|
| 624 | +ERROR: relation "demo" does not exist |
|
| 625 | +LINE 1: SELECT * FROM demo; |
|
| 626 | +``` |
|
| 627 | + |
|
| 628 | +**Oracle 语句级回滚** |
|
| 629 | + |
|
| 630 | +如果在执行过程中的任何时候,SQL 语句发生错误,则该语句的所有更改都将回滚。回滚的效果就好像该语句从未执行过一样。这是一种语句级的回滚。 |
|
| 631 | + |
|
| 632 | +在 SQL 语句执行过程中发生的错误会导致语句级回滚。(此类错误的一个示例是,尝试在主键中插入重复值。在 SQL 语句解析过程中发生的错误(如语法错误)尚未执行,因此不会导致语句级回滚。涉及死锁(争用相同数据)的单个 SQL 语句也可能导致语句级回滚。 |
|
| 633 | + |
|
| 634 | +失败的 SQL 语句只会导致丢失它自己执行的任何工作;它不会导致在当前事务中丢失之前的任何工作。如果该语句是 DDL 语句,则不会撤消紧接在它前面的隐式提交。 |
|
| 635 | + |
|
| 636 | +在 Oracle 中,在一次用户调用中有一个语句失败时,将会回滚该用户调用所做的修改,但不会回滚之前的修改。事务还可以继续(如重试,或执行替代的更改),例如: |
|
| 637 | + |
|
| 638 | +```sql |
|
| 639 | +CREATE TABLE DEMO AS SELECT 1 n, current_timestamp t FROM dual; |
|
| 640 | +ALTER TABLE DEMO ADD UNIQUE(n); |
|
| 641 | + |
|
| 642 | +SELECT * FROM DEMO; |
|
| 643 | + N T |
|
| 644 | +---------- ----------------------------------- |
|
| 645 | + 1 02-AUG-21 11.04.16.507292 PM +00:00 |
|
| 646 | + |
|
| 647 | +INSERT INTO DEMO VALUES (2, current_timestamp); |
|
| 648 | + |
|
| 649 | +SELECT * FROM DEMO; |
|
| 650 | + N T |
|
| 651 | +---------- ----------------------------------- |
|
| 652 | + 1 02-AUG-21 11.04.16.507292 PM +00:00 |
|
| 653 | + 2 02-AUG-21 11.04.16.601105 PM +00:00 |
|
| 654 | + |
|
| 655 | +INSERT INTO DEMO VALUES (1, current_timestamp); |
|
| 656 | +ERROR at line 1: |
|
| 657 | +ORA-00001: unique constraint (DEMO.SYS_C007847) violated |
|
| 658 | + |
|
| 659 | +SELECT * FROM DEMO; |
|
| 660 | + N T |
|
| 661 | +---------- ----------------------------------- |
|
| 662 | + 1 02-AUG-21 11.04.16.507292 PM +00:00 |
|
| 663 | + 2 02-AUG-21 11.04.16.601105 PM +00:00 |
|
| 664 | +``` |
|
| 665 | + |
|
| 666 | +#### 3. 错误原因 |
|
| 667 | + |
|
| 668 | +**3.1 直接原因** |
|
| 669 | + |
|
| 670 | +- **事务中的 SQL 语句执行失败**:如违反唯一约束、主键冲突、语法错误、权限不足等 |
|
| 671 | +- **事务未显式终止**:失败后未执行 `ROLLBACK` 或 `COMMIT`,事务块未关闭 |
|
| 672 | + |
|
| 673 | +**3.2 常见触发场景** |
|
| 674 | + |
|
| 675 | +| 场景 | 示例 | |
|
| 676 | +| ---------------------- | ------------------------------------------------------------ | |
|
| 677 | +| 插入重复的主键或唯一键 | `INSERT INTO users (id) VALUES (1);`(若 `id=1` 已存在) | |
|
| 678 | +| 语法错误 | `INSERT INTO table (invalid_column) VALUES (1);`(列名错误) | |
|
| 679 | +| 权限不足 | 普通用户尝试执行 `DROP TABLE` | |
|
| 680 | +| 隐式事务未处理 | ORM 框架或客户端工具默认开启事务,但未捕获异常并回滚 | |
|
| 681 | + |
|
| 682 | +#### 4. 解决方法 |
|
| 683 | + |
|
| 684 | +**1. 立即终止事务** |
|
| 685 | + |
|
| 686 | +通过 `ROLLBACK` 显式回滚事务,恢复数据库连接的可用状态: |
|
| 687 | + |
|
| 688 | +```sql |
|
| 689 | +ROLLBACK; -- 终止当前事务,清除错误状态 |
|
| 690 | +``` |
|
| 691 | + |
|
| 692 | +**2. 定位错误原因** |
|
| 693 | + |
|
| 694 | +1. **查看客户端返回的错误信息** |
|
| 695 | + |
|
| 696 | + 例如:`duplicate key value violates unique constraint "users_pkey"` |
|
| 697 | + |
|
| 698 | +2. **查询 PostgreSQL 日志** |
|
| 699 | + |
|
| 700 | + - 日志默认路径:`/var/log/postgresql/postgresql-<版本>-main.log` |
|
| 701 | + - 搜索关键词:`ERROR`, `ROLLBACK`, 或事务 ID(如 `process 12345`) |
|
| 702 | + |
|
| 703 | +3. **通过 SQL 获取最近错误** |
|
| 704 | + |
|
| 705 | + ```sql |
|
| 706 | + SELECT pg_last_error(); -- 部分客户端支持(如 psql) |
|
| 707 | + ``` |
|
| 708 | + |
|
| 709 | +**3. 修复并重试事务** |
|
| 710 | + |
|
| 711 | +根据错误原因调整 SQL 逻辑: |
|
| 712 | + |
|
| 713 | +- **主键冲突**:检查重复数据,或使用 `ON CONFLICT` 处理冲突。 |
|
| 714 | + |
|
| 715 | + ```sql |
|
| 716 | + INSERT INTO users (id) VALUES (1) |
|
| 717 | + ON CONFLICT (id) DO NOTHING; |
|
| 718 | + ``` |
|
| 719 | + |
|
| 720 | +- **权限问题**:授予用户权限。 |
|
| 721 | + |
|
| 722 | + ```sql |
|
| 723 | + GRANT INSERT, UPDATE ON table_name TO user_name; |
|
| 724 | + ``` |
|
| 725 | + |
|
| 726 | +#### 5. 高级场景与优化 |
|
| 727 | + |
|
| 728 | +**1. 使用保存点(SAVEPOINT)** |
|
| 729 | + |
|
| 730 | +在长事务中分割操作,允许部分回滚: |
|
| 731 | + |
|
| 732 | +```sql |
|
| 733 | +BEGIN; |
|
| 734 | +INSERT INTO table1 VALUES (1); |
|
| 735 | +SAVEPOINT my_savepoint; -- 设置保存点 |
|
| 736 | +INSERT INTO table2 VALUES (1); -- 假设此处失败 |
|
| 737 | +ROLLBACK TO my_savepoint; -- 回滚到保存点,继续后续操作 |
|
| 738 | +INSERT INTO table3 VALUES (1); |
|
| 739 | +COMMIT; |
|
| 740 | +``` |
|
| 741 | + |
|
| 742 | +#### 6. 预防措施 |
|
| 743 | + |
|
| 744 | +| 措施 | 说明 | |
|
| 745 | +| ------------------ | ----------------------------------------------------------- | |
|
| 746 | +| **短事务原则** | 减少事务执行时间,避免长事务占用锁资源。 | |
|
| 747 | +| **自动提交模式** | 在客户端工具中开启自动提交(`SET AUTOCOMMIT = ON`)。 | |
|
| 748 | +| **异常捕获与回滚** | 在所有数据库操作中强制捕获异常并回滚。 | |
|
| 749 | +| **测试与监控** | 定期模拟错误场景(如主键冲突),验证回滚逻辑是否生效。 | |
|
| 750 | +| **日志分析** | 使用工具(如 pgBadger)分析 PostgreSQL 日志,识别高频错误。 | |
|
| 751 | + |
|
| 752 | + |
|
| 753 | + |
|
| 754 | +## 第 3 节. PostgreSQL 基础教程 |
|
| 755 | + |
|
| 756 | +**来源:** [PostgreSQL 教程](https://www.rockdata.net/zh-cn/tutorial/toc/) |
|
| 757 | + |
|
| 758 | +本 **PostgreSQL 教程**可帮助您快速了解 PostgreSQL。您将通过许多实际示例快速掌握 PostgreSQL,并将这些知识应用于使用 PostgreSQL 开发应用程序。 |
|
| 148 | 759 | |
| 149 | 760 | 如果你是 … |
| 150 | 761 | |
| ... | ... | @@ -158,11 +769,9 @@ PostgreSQL 教程演示了 PostgreSQL 的许多独特功能,这些功能使其 |
| 158 | 769 | |
| 159 | 770 | ### [PostgreSQL 入门](https://www.rockdata.net/zh-cn/tutorial/getting-started/) |
| 160 | 771 | |
| 161 | - |
|
| 162 | - |
|
| 163 | 772 | 本部分向您展示如何在 Windows、Linux 和 macOS 上安装 PostgreSQL,帮助您开始使用 PostgreSQL。您还将学习如何使用 psql 工具连接到 PostgreSQL,以及如何将示例数据库加载到 PostgreSQL 中进行练习。 |
| 164 | 773 | |
| 165 | -## PostgreSQL 基础教程 |
|
| 774 | +### PostgreSQL 基础教程 |
|
| 166 | 775 | |
| 167 | 776 | 首先,您将学习如何使用基本数据查询技术从单个表中查询数据,包括查询数据、对结果集进行排序和过滤行。然后,您将了解高级查询,例如连接多个表、使用集合操作以及构造子查询。最后,您将学习如何管理数据库表,例如创建新表或修改现有表的结构。 |
| 168 | 777 | |
| ... | ... | @@ -350,56 +959,42 @@ PostgreSQL 教程演示了 PostgreSQL 的许多独特功能,这些功能使其 |
| 350 | 959 | - [PostGIS 基础用法](https://www.rockdata.net/zh-cn/tutorial/postgis-basics/) – 向您介绍 PostGIS 的一些基础用法。 |
| 351 | 960 | - [使用 PostGIS 进行基础的地理空间数据查询](https://www.rockdata.net/zh-cn/tutorial/postgis-basic-queries/) – 向您演示用于处理地理空间数据的基础 PostGIS 查询。 |
| 352 | 961 | |
| 353 | -## PostgreSQL 高级教程 |
|
| 354 | 962 | |
| 355 | -这个 PostgreSQL 高级教程涵盖了高级概念,包括存储过程、索引、视图、触发器和数据库管理。 |
|
| 356 | 963 | |
| 357 | -### [PostgreSQL 函数](https://www.rockdata.net/zh-cn/tutorial/postgres-functions/) |
|
| 964 | +# 第 4 节. PostgreSQL 高级教程 |
|
| 358 | 965 | |
| 966 | +这个 PostgreSQL 高级教程涵盖了高级概念,包括存储过程、索引、视图、触发器和数据库管理。 |
|
| 359 | 967 | |
| 968 | +### [PostgreSQL 函数](https://www.rockdata.net/zh-cn/tutorial/postgres-functions/) |
|
| 360 | 969 | |
| 361 | 970 | PostgreSQL 为内置数据类型提供了大量的函数。本节向您展示如何使用一些最常用的 PostgreSQL 函数。 |
| 362 | 971 | |
| 363 | 972 | ### [PostgreSQL PL/pgSQL](https://www.rockdata.net/zh-cn/tutorial/postgres-plpgsql/) |
| 364 | 973 | |
| 365 | - |
|
| 366 | - |
|
| 367 | 974 | 此 PostgreSQL 存储过程部分将逐步向您展示如何使用 PL/pgSQL 过程语言开发 PostgreSQL 用户定义函数。 |
| 368 | 975 | |
| 369 | 976 | ### [PostgreSQL 触发器](https://www.rockdata.net/zh-cn/tutorial/ddl-triggers/) |
| 370 | 977 | |
| 371 | - |
|
| 372 | - |
|
| 373 | 978 | 本节向您介绍 PostgreSQL 触发器概念,并展示如何在 PostgreSQL 中管理触发器。 |
| 374 | 979 | |
| 375 | 980 | ### [PostgreSQL 视图](https://www.rockdata.net/zh-cn/tutorial/ddl-views/) |
| 376 | 981 | |
| 377 | - |
|
| 378 | - |
|
| 379 | 982 | 我们将向您介绍数据库视图概念,并向您展示如何管理视图,例如在数据库中创建、更改和删除视图。 |
| 380 | 983 | |
| 381 | 984 | ### [PostgreSQL 索引](https://www.rockdata.net/zh-cn/tutorial/indexes/) |
| 382 | 985 | |
| 383 | - |
|
| 384 | - |
|
| 385 | 986 | PostgreSQL 索引是增强数据库性能的有效工具。索引可以帮助数据库服务器比没有索引时更快地找到特定行。 |
| 386 | 987 | |
| 387 | 988 | ### [PostgreSQL 优化](https://www.rockdata.net/zh-cn/tutorial/postgres-optimization/) |
| 388 | 989 | |
| 389 | - |
|
| 390 | - |
|
| 391 | 990 | 本节向您介绍 PostgreSQL 性能优化,并展示如何在 PostgreSQL 中优化各种场景的性能问题。 |
| 392 | 991 | |
| 393 | 992 | ### [PostgreSQL 管理](https://www.rockdata.net/zh-cn/tutorial/postgres-admin/) |
| 394 | 993 | |
| 395 | - |
|
| 396 | - |
|
| 397 | 994 | PostgreSQL 管理涵盖 PostgreSQL 数据库服务器最重要的活动,包括角色和数据库管理、备份和恢复。 |
| 398 | 995 | |
| 399 | 996 | ### [PostgreSQL 监控](https://www.rockdata.net/zh-cn/tutorial/postgres-monitoring/) |
| 400 | 997 | |
| 401 | - |
|
| 402 | - |
|
| 403 | 998 | PostgreSQL 监控涵盖 PostgreSQL 数据库服务器最重要的监控和运维活动。 |
| 404 | 999 | |
| 405 | 1000 | ### [应用程序编程接口](https://www.rockdata.net/zh-cn/docs/14/client-interfaces.html) |
| ... | ... | @@ -408,1550 +1003,4 @@ PostgreSQL 监控涵盖 PostgreSQL 数据库服务器最重要的监控和运维 |
| 408 | 1003 | |
| 409 | 1004 | - [PostgreSQL Java 教程](https://www.rockdata.net/zh-cn/tutorial/postgres-java/) – 此 PostgreSQL JDBC 部分向您展示,如何使用 Java JDBC 驱动程序与 PostgreSQL 数据库进行交互。 |
| 410 | 1005 | - [PostgreSQL Python 教程](https://www.rockdata.net/zh-cn/tutorial/postgres-python/) – 此 PostgreSQL Python 部分向您展示,如何使用 Python 编程语言与 PostgreSQL 数据库进行交互。 |
| 411 | -- [使用 Golang 连接到 PostgreSQL](https://www.rockdata.net/zh-cn/tutorial/golang-setup/) – 向您介绍如何使用 Go 编程语言与 PostgreSQL 数据库进行交互。 |
|
| 412 | - |
|
| 413 | - |
|
| 414 | - |
|
| 415 | - |
|
| 416 | - |
|
| 417 | -## 语法差异 |
|
| 418 | - |
|
| 419 | -如果列别名包含一个或多个空格,则需要用双引号将其引起来,如下所示: |
|
| 420 | - |
|
| 421 | - |
|
| 422 | - |
|
| 423 | -## 包含空格的列别名 |
|
| 424 | - |
|
| 425 | -如果列别名包含一个或多个空格,则需要用双引号将其引起来,如下所示: |
|
| 426 | - |
|
| 427 | -```sql |
|
| 428 | -column_name AS "column alias" |
|
| 429 | -``` |
|
| 430 | - |
|
| 431 | -例如: |
|
| 432 | - |
|
| 433 | -```sql |
|
| 434 | -SELECT |
|
| 435 | - first_name || ' ' || last_name "full name" |
|
| 436 | -FROM |
|
| 437 | - customer; |
|
| 438 | -``` |
|
| 439 | - |
|
| 440 | - |
|
| 441 | - |
|
| 442 | - |
|
| 443 | - |
|
| 444 | -## PostgreSQL SELECT DISTINCT 子句简介 |
|
| 445 | - |
|
| 446 | -在这种情况下,`column1`和`column2`列中的值的组合将用于计算重复项。 |
|
| 447 | - |
|
| 448 | -PostgreSQL 还提供了`DISTINCT ON (expression)`来保留每组重复项的第一行的功能,使用以下语法: |
|
| 449 | - |
|
| 450 | -```sql |
|
| 451 | -SELECT |
|
| 452 | - DISTINCT ON (column1) column_alias, |
|
| 453 | - column2 |
|
| 454 | -FROM |
|
| 455 | - table_name |
|
| 456 | -ORDER BY |
|
| 457 | - column1, |
|
| 458 | - column2; |
|
| 459 | -``` |
|
| 460 | - |
|
| 461 | -从`SELECT`语句返回的行的顺序是未指定的,因此每组重复项的第一行也是未指定的。 |
|
| 462 | - |
|
| 463 | -最好始终使用带有`DISTINCT ON(expression)`的 [ORDER BY](https://www.rockdata.net/zh-cn/tutorial/dml-order-by/) 子句,以使结果集可预测。 |
|
| 464 | - |
|
| 465 | -请注意,`DISTINCT ON`表达式必须与`ORDER BY`子句中最左边的表达式匹配。 |
|
| 466 | - |
|
| 467 | - |
|
| 468 | - |
|
| 469 | - |
|
| 470 | - |
|
| 471 | -## PostgreSQL ORDER BY 子句和 NULL |
|
| 472 | - |
|
| 473 | -在数据库世界中,`NULL`是一个标记,指示丢失的数据或数据在记录时未知。 |
|
| 474 | - |
|
| 475 | -对包含`NULL`的行进行排序时,可以使用`ORDER BY`子句的`NULLS FIRST`或`NULLS LAST`选项,指定`NULL`与其他非空值的顺序: |
|
| 476 | - |
|
| 477 | -```sql |
|
| 478 | -ORDER BY sort_expresssion [ASC | DESC] [NULLS FIRST | NULLS LAST] |
|
| 479 | -``` |
|
| 480 | - |
|
| 481 | -在此示例中,`ORDER BY`子句按升序对`sort_demo`表的`num`列中的值进行排序。它将`NULL`置于其他值之后。 |
|
| 482 | - |
|
| 483 | -因此,如果您使用`ASC`选项,`ORDER BY`子句默认使用`NULLS LAST`选项。因此,以下查询返回相同的结果: |
|
| 484 | - |
|
| 485 | -```sql |
|
| 486 | -SELECT num |
|
| 487 | -FROM sort_demo |
|
| 488 | -ORDER BY num NULLS LAST; |
|
| 489 | -``` |
|
| 490 | - |
|
| 491 | -要放置`NULL`在其他非空值之前,可以使用`NULLS FIRST`选项: |
|
| 492 | - |
|
| 493 | -```sql |
|
| 494 | -SELECT num |
|
| 495 | -FROM sort_demo |
|
| 496 | -ORDER BY num NULLS FIRST; |
|
| 497 | -``` |
|
| 498 | - |
|
| 499 | - |
|
| 500 | - |
|
| 501 | - |
|
| 502 | - |
|
| 503 | -## PostgreSQL 的分页和过滤技术 |
|
| 504 | - |
|
| 505 | -[PostgreSQL](https://geek-docs.com/postgresql/postgresql-top-tutorials/1000100_postgresql_index.html) 提供了多种方法来实现分页和过滤功能。其中,键集分页方法是在处理大型表时的一个非常有效的方法。 |
|
| 506 | - |
|
| 507 | -https://www.rockdata.net/zh-cn/tutorial/dml-paginate/ |
|
| 508 | - |
|
| 509 | - |
|
| 510 | - |
|
| 511 | -### 键集分页方法 |
|
| 512 | - |
|
| 513 | -键集分页方法基于结果集中的唯一键(通常是主键)进行分页。它通过保存上一次查询的最后一行的键值,并将其作为下一次查询的起点来实现分页。 |
|
| 514 | - |
|
| 515 | -以下是一个使用键集分页方法的示例查询: |
|
| 516 | - |
|
| 517 | -```sql |
|
| 518 | -SELECT * |
|
| 519 | -FROM large_table |
|
| 520 | -WHERE id > last_key |
|
| 521 | -ORDER BY id |
|
| 522 | -LIMIT 10; |
|
| 523 | -``` |
|
| 524 | - |
|
| 525 | - |
|
| 526 | - |
|
| 527 | -在此示例中,我们使用唯一键 id 进行分页。上一次查询的最后一条数据的 id 值将用于下一次查询的过滤条件。通过以此方式逐步递增分页查询,我们可以避免加载整个结果集,从而提高性能和效率。 |
|
| 528 | - |
|
| 529 | -### OFFSET 和 LIMIT 分页 |
|
| 530 | - |
|
| 531 | -除了键集分页方法外,PostgreSQL 还提供了使用 OFFSET 和 LIMIT 子句进行分页的方式。OFFSET 子句用于指定开始返回结果的位置,LIMIT 子句用于指定返回结果的数量。 |
|
| 532 | - |
|
| 533 | -以下是一个使用 OFFSET 和 LIMIT 分页的示例查询: |
|
| 534 | - |
|
| 535 | -```sql |
|
| 536 | -SELECT * |
|
| 537 | -FROM large_table |
|
| 538 | -ORDER BY id |
|
| 539 | -OFFSET 1000 |
|
| 540 | -LIMIT 10; |
|
| 541 | -``` |
|
| 542 | - |
|
| 543 | -## PostgreSQL LIMIT 子句简介 |
|
| 544 | - |
|
| 545 | -https://www.rockdata.net/zh-cn/tutorial/dml-limit/ |
|
| 546 | - |
|
| 547 | -PostgreSQL 的`LIMIT`是 [SELECT](https://www.rockdata.net/zh-cn/tutorial/dml-select/) 语句的可选子句,用于限制查询返回的行数。 |
|
| 548 | - |
|
| 549 | -下面说明了`LIMIT`子句的语法: |
|
| 550 | - |
|
| 551 | -```sql |
|
| 552 | -SELECT select_list |
|
| 553 | -FROM table_name |
|
| 554 | -ORDER BY sort_expression |
|
| 555 | -LIMIT row_count |
|
| 556 | -``` |
|
| 557 | - |
|
| 558 | -该语句返回查询生成的`row_count`行。如果`row_count`为零,则查询返回空集。如果`row_count`是`NULL`,查询将返回与没有`LIMIT`子句相同的结果集。 |
|
| 559 | - |
|
| 560 | -如果您想在返回`row_count`行之前跳过一些行,请在`LIMIT`子句之后放置`OFFSET`子句,如下所示: |
|
| 561 | - |
|
| 562 | -```sql |
|
| 563 | -SELECT select_list |
|
| 564 | -FROM table_name |
|
| 565 | -LIMIT row_count OFFSET row_to_skip; |
|
| 566 | -``` |
|
| 567 | - |
|
| 568 | -该语句首先跳过`row_to_skip`行,然后返回查询生成的`row_count`行。如果`row_to_skip`为零,则该语句将像没有`OFFSET`子句一样工作。 |
|
| 569 | - |
|
| 570 | -由于表可能以未指定的顺序存储行,因此当您使用`LIMIT`子句时,应始终使用 [ORDER BY](https://www.rockdata.net/zh-cn/tutorial/dml-order-by/) 子句来控制行顺序。如果不使用`ORDER BY`子句,则可能会得到具有未指定行顺序的结果集。 |
|
| 571 | - |
|
| 572 | - |
|
| 573 | - |
|
| 574 | -## PostgreSQL FETCH 子句简介 |
|
| 575 | - |
|
| 576 | -为了限制查询返回的行数,您经常使用`LIMIT`子句。`LIMIT`子句被许多关系数据库管理系统广泛使用,例如 MySQL、H2 和 HSQLDB。但是,`LIMIT`子句不是 SQL 标准。 |
|
| 577 | - |
|
| 578 | -为了符合 SQL 标准,PostgreSQL 支持`FETCH`子句来检索查询返回的行数。 |
|
| 579 | - |
|
| 580 | -> 请注意,`FETCH`子句是在 SQL:2008 中作为 SQL 标准的一部分引入的。 |
|
| 581 | - |
|
| 582 | -下面说明了 PostgreSQL 的`FETCH`子句的语法: |
|
| 583 | - |
|
| 584 | -```sql |
|
| 585 | -OFFSET start { ROW | ROWS } |
|
| 586 | -FETCH { FIRST | NEXT } [ row_count ] { ROW | ROWS } ONLY |
|
| 587 | -``` |
|
| 588 | - |
|
| 589 | -## FETCH 对比 LIMIT |
|
| 590 | - |
|
| 591 | -`FETCH`子句在功能上等同于`LIMIT`子句。如果您计划使您的应用程序与其他数据库系统兼容,则应该使用`FETCH`子句,因为它遵循 SQL 标准。 |
|
| 592 | - |
|
| 593 | - |
|
| 594 | - |
|
| 595 | - |
|
| 596 | - |
|
| 597 | -## PostgreSQL WHERE 子句概述 |
|
| 598 | - |
|
| 599 | -https://www.rockdata.net/zh-cn/tutorial/dml-where/ |
|
| 600 | - |
|
| 601 | -PostgreSQL 的`WHERE`子句的语法如下: |
|
| 602 | - |
|
| 603 | -```sql |
|
| 604 | -SELECT select_list |
|
| 605 | -FROM table_name |
|
| 606 | -WHERE condition |
|
| 607 | -ORDER BY sort_expression |
|
| 608 | -``` |
|
| 609 | - |
|
| 610 | -`WHERE`子句出现在`SELECT`语句的`FROM`子句之后。`WHERE`子句使用`condition`来过滤从`SELECT`列表子句返回的行。 |
|
| 611 | - |
|
| 612 | -`condition`的计算结果必须为真、假或未知。它可以是布尔表达式或使用`AND`和`OR`运算符的布尔表达式的组合。 |
|
| 613 | - |
|
| 614 | -该查询仅返回满足`WHERE`子句中`condition`的行。换句话说,只有导致`condition`计算结果为 true 的行才会包含在结果集中。 |
|
| 615 | - |
|
| 616 | -PostgreSQL 计算`WHERE`子句的时间点,在`FROM`子句之后,在`SELECT`列表和`ORDER BY`子句之前: |
|
| 617 | - |
|
| 618 | -如果在`SELECT`列表子句中使用列别名,则不能在`WHERE`子句中使用它们。 |
|
| 619 | - |
|
| 620 | -除了`SELECT`语句之外,您还可以使用`UPDATE`和`DELETE`语句中的`WHERE`子句来指定要更新或删除的行。 |
|
| 621 | - |
|
| 622 | -要构成`WHERE`子句中的条件,请使用比较运算符和逻辑运算符: |
|
| 623 | - |
|
| 624 | -| 运算符 | 描述 | |
|
| 625 | -| :----------------------------------------------------------- | :-------------------------------------- | |
|
| 626 | -| = | 等于 | |
|
| 627 | -| > | 大于 | |
|
| 628 | -| < | 小于 | |
|
| 629 | -| >= | 大等于 | |
|
| 630 | -| <= | 小等于 | |
|
| 631 | -| <> 或 != | 不等于 | |
|
| 632 | -| AND | 逻辑运算符 AND | |
|
| 633 | -| OR | 逻辑运算符 OR | |
|
| 634 | -| [IN](https://www.rockdata.net/zh-cn/tutorial/dml-in/) | 如果值与列表中的任何值匹配,则返回 true | |
|
| 635 | -| [BETWEEN](https://www.rockdata.net/zh-cn/tutorial/dml-between/) | 如果值介于某个值范围之间,则返回 true | |
|
| 636 | -| [LIKE](https://www.rockdata.net/zh-cn/tutorial/dml-like/) | 如果值与模式匹配则返回 true | |
|
| 637 | -| [IS NULL](https://www.rockdata.net/zh-cn/tutorial/dml-is-null/) | 如果值为 NULL,则返回 true | |
|
| 638 | -| NOT | 对其他运算符的结果求反 | |
|
| 639 | - |
|
| 640 | -### 7) 使用带有不等于运算符 (<>) 的 WHERE 子句示例 |
|
| 641 | - |
|
| 642 | -此示例查找名字以`Bra`开头且姓氏不是`Motley`的客户: |
|
| 643 | - |
|
| 644 | -```sql |
|
| 645 | -SELECT |
|
| 646 | - first_name, |
|
| 647 | - last_name |
|
| 648 | -FROM |
|
| 649 | - customer |
|
| 650 | -WHERE |
|
| 651 | - first_name LIKE 'Bra%' AND |
|
| 652 | - last_name <> 'Motley'; |
|
| 653 | -``` |
|
| 654 | - |
|
| 655 | - |
|
| 656 | - |
|
| 657 | -## PostgreSQL BETWEEN 运算符简介 |
|
| 658 | - |
|
| 659 | -您可以使用`BETWEEN`运算符将一个值与一系列值进行匹配。下面说明了`BETWEEN`运算符的语法: |
|
| 660 | - |
|
| 661 | -```sql |
|
| 662 | -value BETWEEN low AND high; |
|
| 663 | -``` |
|
| 664 | - |
|
| 665 | -如果`value`大等于`low`值且小等于`high`值,则表达式返回 true,否则返回 false。 |
|
| 666 | - |
|
| 667 | -您可以使用大等于 (`>=`) 或小等于 (`<=`) 运算符重写`BETWEEN`运算符,如下所示: |
|
| 668 | - |
|
| 669 | -```sql |
|
| 670 | -value >= low and value <= high |
|
| 671 | -``` |
|
| 672 | - |
|
| 673 | -如果要检查值是否超出范围,可以将`NOT`运算符与`BETWEEN`运算符组合起来,如下所示: |
|
| 674 | - |
|
| 675 | -```sql |
|
| 676 | -value NOT BETWEEN low AND high; |
|
| 677 | -``` |
|
| 678 | - |
|
| 679 | -以下表达式等效于使用`NOT`和`BETWEEN`运算符的表达式: |
|
| 680 | - |
|
| 681 | -```sql |
|
| 682 | -value < low OR value > high |
|
| 683 | -``` |
|
| 684 | - |
|
| 685 | - |
|
| 686 | - |
|
| 687 | -如果要检查日期范围内的值,则应使用 ISO 8601 格式的文字日期,即 YYYY-MM-DD。例如,要获取付款日期在`2007-02-07`和`2007-02-15`之间的付款,请使用以下查询: |
|
| 688 | - |
|
| 689 | -```sql |
|
| 690 | -SELECT |
|
| 691 | - customer_id, |
|
| 692 | - payment_id, |
|
| 693 | - amount, |
|
| 694 | - payment_date |
|
| 695 | -FROM |
|
| 696 | - payment |
|
| 697 | -WHERE |
|
| 698 | - payment_date BETWEEN '2007-02-07' AND '2007-02-15'; |
|
| 699 | -``` |
|
| 700 | - |
|
| 701 | - |
|
| 702 | - |
|
| 703 | - |
|
| 704 | - |
|
| 705 | -## PostgreSQL LIKE 运算符简介 |
|
| 706 | - |
|
| 707 | -假设您想要找到一位客户,但您不记得她的确切名字。但是,您可以记得她的名字以类似`Jen`开头。 |
|
| 708 | - |
|
| 709 | -如何从数据库中找到准确的客户?您可以通过查看名字列来查找`customer`表中的客户,看看是否有任何以`Jen`开头的值。但是,如果客户表包含大量行,则此过程可能会非常耗时。 |
|
| 710 | - |
|
| 711 | -幸运的是,您可以使用 PostgreSQL 的`LIKE`运算符,通过以下查询将客户的名字与字符串进行匹配: |
|
| 712 | - |
|
| 713 | -```sql |
|
| 714 | -SELECT |
|
| 715 | - first_name, |
|
| 716 | - last_name |
|
| 717 | -FROM |
|
| 718 | - customer |
|
| 719 | -WHERE |
|
| 720 | - first_name LIKE 'Jen%'; |
|
| 721 | -``` |
|
| 722 | - |
|
| 723 | - |
|
| 724 | - |
|
| 725 | -请注意,其中`WHERE`子句包含一个特殊表达式:`first_name`、`LIKE`运算符和包含百分号 (`%`) 的字符串。字符串`'Jen%'`称为模式。 |
|
| 726 | - |
|
| 727 | -该查询返回`first_name`列值以`Jen`开头且后跟任意字符序列的行。这种技术称为模式匹配。 |
|
| 728 | - |
|
| 729 | -您可以通过将文字值与通配符组合来构造模式,并使用`LIKE`或`NOT LIKE`运算符来查找匹配项。PostgreSQL 为您提供了两个通配符: |
|
| 730 | - |
|
| 731 | -- 百分号 (`%`) 匹配任何零个或多个字符的序列。 |
|
| 732 | -- 下划线符号 (`_`) 匹配任何单个字符。 |
|
| 733 | - |
|
| 734 | -PostgreSQL `LIKE`运算符的语法如下: |
|
| 735 | - |
|
| 736 | -```sql |
|
| 737 | -value LIKE pattern |
|
| 738 | -``` |
|
| 739 | - |
|
| 740 | -如果`value`与`pattern`匹配,则表达式返回 true。 |
|
| 741 | - |
|
| 742 | -要否定`LIKE`运算符,请按如下方式使用`NOT`运算符: |
|
| 743 | - |
|
| 744 | -```sql |
|
| 745 | -value NOT LIKE pattern |
|
| 746 | -``` |
|
| 747 | - |
|
| 748 | -当`value`与`pattern`不匹配时,`NOT LIKE`运算符返回 true。 |
|
| 749 | - |
|
| 750 | -如果模式不包含任何通配符,则`LIKE`运算符的行为类似于等于 (`=`) 运算符。 |
|
| 751 | - |
|
| 752 | - |
|
| 753 | - |
|
| 754 | -## PostgreSQL 对 LIKE 运算符的扩展 |
|
| 755 | - |
|
| 756 | -PostgreSQL 支持类似于`LIKE`运算符的`ILIKE`运算符。此外,`ILIKE`运算符匹配值时不区分大小写。例如: |
|
| 757 | - |
|
| 758 | -```sql |
|
| 759 | -SELECT |
|
| 760 | - first_name, |
|
| 761 | - last_name |
|
| 762 | -FROM |
|
| 763 | - customer |
|
| 764 | -WHERE |
|
| 765 | - first_name ILIKE 'BAR%'; |
|
| 766 | -``` |
|
| 767 | - |
|
| 768 | -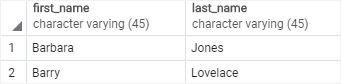 |
|
| 769 | - |
|
| 770 | -模式`BAR%`匹配以`BAR`、`Bar`、`BaR`等开头的任何字符串。如果您改用`LIKE`运算符,查询将不会返回任何行。 |
|
| 771 | - |
|
| 772 | -PostgreSQL 还提供了一些类似于`LIKE`, `NOT LIKE`, `ILIKE`和`NOT ILIKE`的运算符,如下所示: |
|
| 773 | - |
|
| 774 | -| 运算符 | 等价于 | |
|
| 775 | -| :----- | :-------- | |
|
| 776 | -| ~~ | LIKE | |
|
| 777 | -| ~~* | ILIKE | |
|
| 778 | -| !~~ | NOT LIKE | |
|
| 779 | -| !~~* | NOT ILIKE | |
|
| 780 | - |
|
| 781 | -在本教程中,您学习了如何使用 PostgreSQL 的`LIKE`和`ILIKE`运算符,通过模式匹配来查询数据。 |
|
| 782 | - |
|
| 783 | - |
|
| 784 | - |
|
| 785 | - |
|
| 786 | - |
|
| 787 | -## NULL 和 IS NULL 运算符简介 |
|
| 788 | - |
|
| 789 | -在数据库世界中,NULL 意味着缺少信息或不适用。NULL 不是一个值,因此,您不能将它与任何其他值(例如数字或字符串)进行比较。NULL 与值的比较将始终得到 NULL,这意味着结果未知。 |
|
| 790 | - |
|
| 791 | -此外,NULL 不等于 NULL,因此以下表达式返回 NULL: |
|
| 792 | - |
|
| 793 | -```sql |
|
| 794 | -NULL = NULL |
|
| 795 | -``` |
|
| 796 | - |
|
| 797 | -假设您有一个`contacts`表存储联系人的名字、姓氏、电子邮件和电话号码。在记录联系人时,您可能不知道联系人的电话号码。 |
|
| 798 | - |
|
| 799 | -为了解决这个问题,您可以将`phone`列定义为可为空列,并在保存联系人信息时将 NULL [插入](https://www.rockdata.net/zh-cn/tutorial/dml-insert/)到`phone`列中。 |
|
| 800 | - |
|
| 801 | -```sql |
|
| 802 | -CREATE TABLE contacts( |
|
| 803 | - id INT GENERATED BY DEFAULT AS IDENTITY, |
|
| 804 | - first_name VARCHAR(50) NOT NULL, |
|
| 805 | - last_name VARCHAR(50) NOT NULL, |
|
| 806 | - email VARCHAR(255) NOT NULL, |
|
| 807 | - phone VARCHAR(15), |
|
| 808 | - PRIMARY KEY (id) |
|
| 809 | -); |
|
| 810 | -``` |
|
| 811 | - |
|
| 812 | -因此,要获取电话列中没有存储任何电话号码的联系人,请使用以下语句: |
|
| 813 | - |
|
| 814 | -```sql |
|
| 815 | -SELECT |
|
| 816 | - id, |
|
| 817 | - first_name, |
|
| 818 | - last_name, |
|
| 819 | - email, |
|
| 820 | - phone |
|
| 821 | -FROM |
|
| 822 | - contacts |
|
| 823 | -WHERE |
|
| 824 | - phone IS NULL; |
|
| 825 | -``` |
|
| 826 | - |
|
| 827 | -## IS NOT NULL 运算符 |
|
| 828 | - |
|
| 829 | -要检查值是否不为 NULL,请使用`IS NOT NULL`运算符: |
|
| 830 | - |
|
| 831 | -```sql |
|
| 832 | -value IS NOT NULL |
|
| 833 | -``` |
|
| 834 | - |
|
| 835 | -如果值不为 NULL,则表达式返回 true;如果值为 NULL,则表达式返回 false。 |
|
| 836 | - |
|
| 837 | -例如,要查找有电话号码的联系人,您可以使用以下语句: |
|
| 838 | - |
|
| 839 | -```sql |
|
| 840 | -SELECT |
|
| 841 | - id, |
|
| 842 | - first_name, |
|
| 843 | - last_name, |
|
| 844 | - email, |
|
| 845 | - phone |
|
| 846 | -FROM |
|
| 847 | - contacts |
|
| 848 | -WHERE |
|
| 849 | - phone IS NOT NULL; |
|
| 850 | -``` |
|
| 851 | - |
|
| 852 | - |
|
| 853 | - |
|
| 854 | - |
|
| 855 | - |
|
| 856 | -### 3) 使用 DELETE 从表中删除多行 |
|
| 857 | - |
|
| 858 | -以下语句从`links`表中删除两行并返回已删除行的`id`列中的值: |
|
| 859 | - |
|
| 860 | -```sql |
|
| 861 | -DELETE FROM links |
|
| 862 | -WHERE id IN (6,5) |
|
| 863 | -RETURNING *; |
|
| 864 | -``` |
|
| 865 | - |
|
| 866 | -输出: |
|
| 867 | - |
|
| 868 | -### 4) 使用 DELETE 删除表中的所有行 |
|
| 869 | - |
|
| 870 | -以下语句使用不带`WHERE`子句的`DELETE`语句删除`links`表中的所有行: |
|
| 871 | - |
|
| 872 | -```sql |
|
| 873 | -DELETE FROM links; |
|
| 874 | -``` |
|
| 875 | - |
|
| 876 | -现在`links`表是空的。 |
|
| 877 | - |
|
| 878 | - |
|
| 879 | - |
|
| 880 | - |
|
| 881 | - |
|
| 882 | -## PostgreSQL upsert 简介 |
|
| 883 | - |
|
| 884 | -在关系数据库中,术语 upsert 称为合并。这个想法是,当您[向表中插入新行](https://www.rockdata.net/zh-cn/tutorial/dml-insert/)时,如果该行已存在,PostgreSQL 将[更新](https://www.rockdata.net/zh-cn/tutorial/dml-update/)该行,否则,它将插入新行。这就是为什么我们称该操作为 upsert(更新或插入的组合)。 |
|
| 885 | - |
|
| 886 | -要在 PostgreSQL 中使用 upsert 功能,请使用`INSERT ON CONFLICT`语句,如下: |
|
| 887 | - |
|
| 888 | -```postgresql |
|
| 889 | -INSERT INTO table_name(column_list) |
|
| 890 | -VALUES(value_list) |
|
| 891 | -ON CONFLICT target action; |
|
| 892 | -``` |
|
| 893 | - |
|
| 894 | -PostgreSQL 在`INSERT`语句中添加了`ON CONFLICT target action`子句以支持 upsert 功能。 |
|
| 895 | - |
|
| 896 | -在此语句中,`target`可以是以下之一: |
|
| 897 | - |
|
| 898 | -- `(column_name)` – 列名称。 |
|
| 899 | -- `ON CONSTRAINT constraint_name` – 其中约束名称可以是 [UNIQUE 约束](https://www.rockdata.net/zh-cn/tutorial/constraint-unique/)的名称。 |
|
| 900 | -- `WHERE predicate` –带有谓词的[WHERE 子句](https://www.rockdata.net/zh-cn/tutorial/dml-where/)。 |
|
| 901 | - |
|
| 902 | -`action`可以是以下之一: |
|
| 903 | - |
|
| 904 | -- `DO NOTHING` – 表示如果该行已存在于表中,则不执行任何操作。 |
|
| 905 | -- `DO UPDATE SET column_1 = value_1, .. WHERE condition` – 更新表中的一些字段。 |
|
| 906 | - |
|
| 907 | -> 请注意,`ON CONFLICT`子句仅在 PostgreSQL 9.5 和以上版本可用。如果您使用的是早期版本,则需要一种解决方法才能拥有更新插入功能。 |
|
| 908 | - |
|
| 909 | -如果你也在使用 MySQL,你会发现 upsert 功能与 MySQL 中的`insert on duplicate key update`语句类似。 |
|
| 910 | - |
|
| 911 | - |
|
| 912 | - |
|
| 913 | -以下语句与上面的语句等效,但它使用`name`列而不是唯一约束名称作为`INSERT`语句的目标。 |
|
| 914 | - |
|
| 915 | -```postgresql |
|
| 916 | -INSERT INTO customers (name, email) |
|
| 917 | -VALUES('Microsoft','hotline@microsoft.com') |
|
| 918 | -ON CONFLICT (name) |
|
| 919 | -DO NOTHING; |
|
| 920 | -``` |
|
| 921 | - |
|
| 922 | -假设,您想在插入已存在的客户时将新电子邮件与旧电子邮件连接起来,在这种情况下,您使用`UPDATE`子句作为`INSERT`语句的操作,如下所示: |
|
| 923 | - |
|
| 924 | -```postgresql |
|
| 925 | -INSERT INTO customers (name, email) |
|
| 926 | -VALUES('Microsoft','hotline@microsoft.com') |
|
| 927 | -ON CONFLICT (name) |
|
| 928 | -DO |
|
| 929 | - UPDATE SET email = EXCLUDED.email || ';' || customers.email; |
|
| 930 | -``` |
|
| 931 | - |
|
| 932 | - |
|
| 933 | - |
|
| 934 | - |
|
| 935 | - |
|
| 936 | - |
|
| 937 | - |
|
| 938 | -## 子事务简介 |
|
| 939 | - |
|
| 940 | -在专业的应用程序中,很难在不遇到任何错误的情况下编写相当长的事务。为了解决这个问题,用户可以使用一种叫做 SAVEPOINT 的东西。顾名思义,保存点是事务中的一个安全位置,如果出现严重错误,应用程序可以返回到该位置。 |
|
| 941 | - |
|
| 942 | -保存点是一个数据库特性,它允许您在事务中创建命名点,以后可以回滚到该命名点,同时保持事务的其余部分不变。当您想要处理事务中的错误或异常,并有选择地回滚到事务中的特定点,而不必撤消到目前为止所做的所有更改时,保存点非常有用。 |
|
| 943 | - |
|
| 944 | -## 怎么工作的 |
|
| 945 | - |
|
| 946 | -以下是在 PostgreSQL 中使用保存点的方法: |
|
| 947 | - |
|
| 948 | -使用`BEGIN`语句启动一个事务: |
|
| 949 | - |
|
| 950 | -```postgresql |
|
| 951 | -BEGIN; |
|
| 952 | -``` |
|
| 953 | - |
|
| 954 | -这将开始一个新的事务。 |
|
| 955 | - |
|
| 956 | -在事务中,您可以使用`SAVEPOINT`语句创建一个保存点,并指定一个名称: |
|
| 957 | - |
|
| 958 | -```postgresql |
|
| 959 | -SAVEPOINT my_savepoint; |
|
| 960 | -``` |
|
| 961 | - |
|
| 962 | -在此示例中,在事务中创建了一个名为`my_savepoint`的保存点。 |
|
| 963 | - |
|
| 964 | -在事务中执行一个或多个 SQL 操作,例如`INSERT`、`UPDATE`、`DELETE`等。 |
|
| 965 | - |
|
| 966 | -在任何时候,如果需要回滚到保存点,可以使用`ROLLBACK TO`语句: |
|
| 967 | - |
|
| 968 | -```postgresql |
|
| 969 | -ROLLBACK TO my_savepoint; |
|
| 970 | -``` |
|
| 971 | - |
|
| 972 | -这将撤消在创建`my_savepoint`保存点后所做的所有更改,从而有效地将事务还原到该点。 |
|
| 973 | - |
|
| 974 | -您还可以使用`RELEASE`语句释放保存点: |
|
| 975 | - |
|
| 976 | -```postgresql |
|
| 977 | -RELEASE my_savepoint; |
|
| 978 | -``` |
|
| 979 | - |
|
| 980 | -这将删除保存点,并允许事务从当前位置继续。 |
|
| 981 | - |
|
| 982 | -最后,当您准备好提交事务中所做的所有更改时,可以使用`COMMIT`语句: |
|
| 983 | - |
|
| 984 | -```postgresql |
|
| 985 | -COMMIT; |
|
| 986 | -``` |
|
| 987 | - |
|
| 988 | -这会将事务中所做的所有更改保存到数据库中。 |
|
| 989 | - |
|
| 990 | -## 示例 |
|
| 991 | - |
|
| 992 | -下面是一个完整的示例: |
|
| 993 | - |
|
| 994 | -```postgresql |
|
| 995 | -CREATE TABLE test0 AS SELECT 1 AS i; |
|
| 996 | --- Start a main transaction |
|
| 997 | -BEGIN; |
|
| 998 | --- Perform some operations within the transaction |
|
| 999 | -UPDATE test0 SET i = i + 1; |
|
| 1000 | --- Start a subtransaction |
|
| 1001 | -SAVEPOINT s1; |
|
| 1002 | --- Continue with more operations |
|
| 1003 | -UPDATE test0 SET i = i - 1000; |
|
| 1004 | --- Check the content in the table |
|
| 1005 | -SELECT * FROM test0; |
|
| 1006 | - i |
|
| 1007 | ------- |
|
| 1008 | - -998 |
|
| 1009 | -(1 row) |
|
| 1010 | --- Something went wrong, let's roll back to the savepoint |
|
| 1011 | -ROLLBACK TO SAVEPOINT s1; |
|
| 1012 | --- Continue with other operations |
|
| 1013 | -UPDATE test0 SET i = i + 1; |
|
| 1014 | --- Finally, when everything is fine, commit the transaction |
|
| 1015 | -COMMIT; |
|
| 1016 | --- Check the content in the table again |
|
| 1017 | -SELECT * FROM test0; |
|
| 1018 | - i |
|
| 1019 | ---- |
|
| 1020 | - 3 |
|
| 1021 | -(1 row) |
|
| 1022 | -``` |
|
| 1023 | - |
|
| 1024 | - |
|
| 1025 | - |
|
| 1026 | - |
|
| 1027 | - |
|
| 1028 | -## 13.3. 显式锁定 |
|
| 1029 | - |
|
| 1030 | -- [13.3.1. 表级锁](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#LOCKING-TABLES) |
|
| 1031 | -- [13.3.2. 行级锁](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#LOCKING-ROWS) |
|
| 1032 | -- [13.3.3. 页级锁](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#LOCKING-PAGES) |
|
| 1033 | -- [13.3.4. 死锁](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#LOCKING-DEADLOCKS) |
|
| 1034 | -- [13.3.5. 咨询锁](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#ADVISORY-LOCKS) |
|
| 1035 | - |
|
| 1036 | - |
|
| 1037 | - |
|
| 1038 | -PostgreSQL提供了多种锁模式用于控制对表中数据的并发访问。 这些模式可以用于在MVCC无法给出期望行为的情境中由应用控制的锁。 同样,大多数PostgreSQL命令会自动要求恰当的锁以保证被引用的表在命令的执行过程中 不会以一种不兼容的方式删除或修改(例如,`TRUNCATE`无法安全地与同一表中上的其他操作并发地执行,因此它在表上获得一个`ACCESS EXCLUSIVE` 锁来强制这种行为)。 |
|
| 1039 | - |
|
| 1040 | -要检查在一个数据库服务器中当前未解除的锁列表,可以使用[`pg_locks`](https://www.rockdata.net/zh-cn/docs/14/view-pg-locks.html)系统视图。 有关监控锁管理器子系统状态的更多信息,请参考[第 28 章](https://www.rockdata.net/zh-cn/docs/14/monitoring.html)。 |
|
| 1041 | - |
|
| 1042 | -### 13.3.1. 表级锁 |
|
| 1043 | - |
|
| 1044 | - |
|
| 1045 | - |
|
| 1046 | -下面的列表显示了可用的锁模式和PostgreSQL自动使用它们的场合。 你也可以用[LOCK](https://www.rockdata.net/zh-cn/docs/14/sql-lock.html)命令显式获得这些锁。请记住所有这些锁模式都是表级锁,即使它们的名字包含“row”单词(这些名称是历史遗产)。 在一定程度上,这些名字反应了每种锁模式的典型用法 — 但是语意却都是一样的。 两种锁模式之间真正的区别是它们有着不同的冲突锁模式集合(参考[表 13.2](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#TABLE-LOCK-COMPATIBILITY))。 两个事务在同一时刻不能在同一个表上持有属于相互冲突模式的锁(但是,一个事务决不会和自身冲突。例如,它可以在同一个表上获得`ACCESS EXCLUSIVE`锁然后接着获取`ACCESS SHARE`锁)。非冲突锁模式可以由许多事务同时持有。 请特别注意有些锁模式是自冲突的(例如,在一个时刻`ACCESS EXCLUSIVE`锁不能被多于一个事务持有)而其他锁模式不是自冲突的(例如,`ACCESS SHARE`锁可以被多个事务持有)。 |
|
| 1047 | - |
|
| 1048 | -**表级锁模式** |
|
| 1049 | - |
|
| 1050 | -- `ACCESS SHARE` |
|
| 1051 | - |
|
| 1052 | - 只与`ACCESS EXCLUSIVE`锁模式冲突。`SELECT`命令在被引用的表上获得一个这种模式的锁。通常,任何只***读取\***表而不修改它的查询都将获得这种锁模式。 |
|
| 1053 | - |
|
| 1054 | -- `ROW SHARE` |
|
| 1055 | - |
|
| 1056 | - 与`EXCLUSIVE`和`ACCESS EXCLUSIVE`锁模式冲突。`SELECT FOR UPDATE`和`SELECT FOR SHARE`命令在目标表上取得一个这种模式的锁 (加上在被引用但没有选择`FOR UPDATE/FOR SHARE`的任何其他表上的`ACCESS SHARE`锁)。 |
|
| 1057 | - |
|
| 1058 | -- `ROW EXCLUSIVE` |
|
| 1059 | - |
|
| 1060 | - 与`SHARE`、`SHARE ROW EXCLUSIVE`、`EXCLUSIVE`和`ACCESS EXCLUSIVE`锁模式冲突。命令`UPDATE`、`DELETE`和`INSERT`在目标表上取得这种锁模式(加上在任何其他被引用表上的`ACCESS SHARE`锁)。通常,这种锁模式将被任何***修改表中数据\***的命令取得。 |
|
| 1061 | - |
|
| 1062 | -- `SHARE UPDATE EXCLUSIVE` |
|
| 1063 | - |
|
| 1064 | - 与`SHARE UPDATE EXCLUSIVE`、`SHARE`、`SHARE ROW EXCLUSIVE`、`EXCLUSIVE`和`ACCESS EXCLUSIVE`锁模式冲突。这种模式保护一个表不受并发模式改变和`VACUUM`运行的影响。由`VACUUM`(不带`FULL`)、`ANALYZE`、 `CREATE INDEX CONCURRENTLY`、`REINDEX CONCURRENTLY`、 `CREATE STATISTICS`以及某些[`ALTER INDEX`](https://www.rockdata.net/zh-cn/docs/14/sql-alterindex.html) 和 [`ALTER TABLE`](https://www.rockdata.net/zh-cn/docs/14/sql-altertable.html)的变体获得(详细内容请参考这些命令的文档)。 |
|
| 1065 | - |
|
| 1066 | -- `SHARE` |
|
| 1067 | - |
|
| 1068 | - 与`ROW EXCLUSIVE`、`SHARE UPDATE EXCLUSIVE`、`SHARE ROW EXCLUSIVE`、`EXCLUSIVE`和`ACCESS EXCLUSIVE`锁模式冲突。这种模式保护一个表不受并发数据改变的影响。由`CREATE INDEX`(不带`CONCURRENTLY`)取得。 |
|
| 1069 | - |
|
| 1070 | -- `SHARE ROW EXCLUSIVE` |
|
| 1071 | - |
|
| 1072 | - 与`ROW EXCLUSIVE`、`SHARE UPDATE EXCLUSIVE`、`SHARE`、`SHARE ROW EXCLUSIVE`、`EXCLUSIVE`和`ACCESS EXCLUSIVE`锁模式冲突。这种模式保护一个表不受并发数据修改所影响,并且是自排他的,这样在一个时刻只能有一个会话持有它。由`CREATE TRIGGER`和某些形式的 [`ALTER TABLE`](https://www.rockdata.net/zh-cn/docs/14/sql-altertable.html)所获得。 |
|
| 1073 | - |
|
| 1074 | -- `EXCLUSIVE` |
|
| 1075 | - |
|
| 1076 | - 与`ROW SHARE`、`ROW EXCLUSIVE`、`SHARE UPDATE EXCLUSIVE`、`SHARE`、`SHARE ROW EXCLUSIVE`、`EXCLUSIVE`和`ACCESS EXCLUSIVE`锁模式冲突。这种模式只允许并发的`ACCESS SHARE`锁,即只有来自于表的读操作可以与一个持有该锁模式的事务并行处理。由`REFRESH MATERIALIZED VIEW CONCURRENTLY`获得。 |
|
| 1077 | - |
|
| 1078 | -- `ACCESS EXCLUSIVE` |
|
| 1079 | - |
|
| 1080 | - 与所有模式的锁冲突(`ACCESS SHARE`、`ROW SHARE`、`ROW EXCLUSIVE`、`SHARE UPDATE EXCLUSIVE`、`SHARE`、`SHARE ROW EXCLUSIVE`、`EXCLUSIVE`和`ACCESS EXCLUSIVE`)。这种模式保证持有者是访问该表的唯一事务。由`ALTER TABLE`、`DROP TABLE`、`TRUNCATE`、`REINDEX`、`CLUSTER`、`VACUUM FULL`和`REFRESH MATERIALIZED VIEW`(不带`CONCURRENTLY`)命令获取。 很多形式的`ALTER INDEX`和`ALTER TABLE`也在这个层面上获得锁(见[ALTER TABLE](https://www.rockdata.net/zh-cn/docs/14/sql-altertable.html))。这也是未显式指定模式的`LOCK TABLE`命令的默认锁模式。 |
|
| 1081 | - |
|
| 1082 | -### 提示 |
|
| 1083 | - |
|
| 1084 | -只有一个`ACCESS EXCLUSIVE`锁阻塞一个`SELECT`(不带`FOR UPDATE/SHARE`)语句。 |
|
| 1085 | - |
|
| 1086 | -一旦被获取,一个锁通常将被持有直到事务结束。 但是如果在建立保存点之后才获得锁,那么在回滚到这个保存点的时候将立即释放该锁。 这与`ROLLBACK`取消保存点之后所有的影响的原则保持一致。 同样的原则也适用于在PL/pgSQL异常块中获得的锁:一个跳出块的错误将释放在块中获得的锁。 |
|
| 1087 | - |
|
| 1088 | -**表 13.2. 冲突的锁模式** |
|
| 1089 | - |
|
| 1090 | -| 请求的锁模式 | 已存在的锁模式 | | | | | | | | |
|
| 1091 | -| -------------------- | -------------- | ----------- | -------------------- | ------- | ----------------- | ------- | -------------- | ---- | |
|
| 1092 | -| `ACCESS SHARE` | `ROW SHARE` | `ROW EXCL.` | `SHARE UPDATE EXCL.` | `SHARE` | `SHARE ROW EXCL.` | `EXCL.` | `ACCESS EXCL.` | | |
|
| 1093 | -| `ACCESS SHARE` | | | | | | | | X | |
|
| 1094 | -| `ROW SHARE` | | | | | | | X | X | |
|
| 1095 | -| `ROW EXCL.` | | | | | X | X | X | X | |
|
| 1096 | -| `SHARE UPDATE EXCL.` | | | | X | X | X | X | X | |
|
| 1097 | -| `SHARE` | | | X | X | | X | X | X | |
|
| 1098 | -| `SHARE ROW EXCL.` | | | X | X | X | X | X | X | |
|
| 1099 | -| `EXCL.` | | X | X | X | X | X | X | X | |
|
| 1100 | -| `ACCESS EXCL.` | X | X | X | X | X | X | X | X | |
|
| 1101 | - |
|
| 1102 | -### 13.3.2. 行级锁 |
|
| 1103 | - |
|
| 1104 | -除了表级锁以外,还有行级锁,在下文列出了行级锁以及在哪些情境下PostgreSQL会自动使用它们。 行级锁的完整冲突表请见[表 13.3](https://www.rockdata.net/zh-cn/docs/14/explicit-locking.html#ROW-LOCK-COMPATIBILITY)。注意一个事务可能会在相同的行上保持冲突的锁,甚至是在不同的子事务中。 但是除此之外,两个事务永远不可能在相同的行上持有冲突的锁。行级锁不影响数据查询,它们只阻塞对同一行的***写入者和加锁者\***。 行级锁在事务结束时或保存点回滚的时候释放,就像表级锁一样。 |
|
| 1105 | - |
|
| 1106 | -**行级锁模式** |
|
| 1107 | - |
|
| 1108 | -- `FOR UPDATE` |
|
| 1109 | - |
|
| 1110 | - `FOR UPDATE`会导致由`SELECT`语句检索到的行被锁定,就好像它们要被更新。这可以阻止它们被其他事务锁定、修改或者删除,一直到当前事务结束。也就是说其他尝试`UPDATE`、`DELETE`、`SELECT FOR UPDATE`、`SELECT FOR NO KEY UPDATE`、`SELECT FOR SHARE`或者`SELECT FOR KEY SHARE`这些行的事务将被阻塞,直到当前事务结束。反过来,`SELECT FOR UPDATE`将等待已经在相同行上运行以上这些命令的并发事务,并且接着锁定并且返回被更新的行(或者没有行,因为行可能已被删除)。不过,在一个`REPEATABLE READ`或`SERIALIZABLE`事务中,如果一个要被锁定的行在事务开始后被更改,将会抛出一个错误。进一步的讨论请见[第 13.4 节](https://www.rockdata.net/zh-cn/docs/14/applevel-consistency.html)。任何在一行上的`DELETE`命令也会获得`FOR UPDATE`锁模式,以及修改某些列的值的`UPDATE`也会获得该锁模式。 当前`UPDATE`情况中被考虑的列集合是那些具有能用于外键的唯一索引的列(所以部分索引和表达式索引不被考虑),但是这种要求未来有可能会改变。 |
|
| 1111 | - |
|
| 1112 | -- `FOR NO KEY UPDATE` |
|
| 1113 | - |
|
| 1114 | - 行为与`FOR UPDATE`类似,不过获得的锁较弱:这种锁将不会阻塞尝试在相同行上获得锁的`SELECT FOR KEY SHARE`命令。任何不获取`FOR UPDATE`锁的`UPDATE`也会获得这种锁模式。 |
|
| 1115 | - |
|
| 1116 | -- `FOR SHARE` |
|
| 1117 | - |
|
| 1118 | - 行为与`FOR NO KEY UPDATE`类似,不过它在每个检索到的行上获得一个共享锁而不是排他锁。一个共享锁会阻塞其他事务在这些行上执行`UPDATE`、`DELETE`、`SELECT FOR UPDATE`或者`SELECT FOR NO KEY UPDATE`,但是它不会阻止它们执行`SELECT FOR SHARE`或者`SELECT FOR KEY SHARE`。 |
|
| 1119 | - |
|
| 1120 | -- `FOR KEY SHARE` |
|
| 1121 | - |
|
| 1122 | - 行为与`FOR SHARE`类似,不过锁较弱:`SELECT FOR UPDATE`会被阻塞,但是`SELECT FOR NO KEY UPDATE`不会被阻塞。一个键共享锁会阻塞其他事务执行修改键值的`DELETE`或者`UPDATE`,但不会阻塞其他`UPDATE`,也不会阻止`SELECT FOR NO KEY UPDATE`、`SELECT FOR SHARE`或者`SELECT FOR KEY SHARE`。 |
|
| 1123 | - |
|
| 1124 | -PostgreSQL不会在内存里保存任何关于已修改行的信息,因此对一次锁定的行数没有限制。 不过,锁住一行会导致一次磁盘写,例如, `SELECT FOR UPDATE`将修改选中的行以标记它们被锁住,并且因此会导致磁盘写入。 |
|
| 1125 | - |
|
| 1126 | -**表 13.3. 冲突的行级锁** |
|
| 1127 | - |
|
| 1128 | -| 要求的锁模式 | 当前的锁模式 | | | | |
|
| 1129 | -| ----------------- | ------------ | ----------------- | ---------- | ---- | |
|
| 1130 | -| FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE | | |
|
| 1131 | -| FOR KEY SHARE | | | | X | |
|
| 1132 | -| FOR SHARE | | | X | X | |
|
| 1133 | -| FOR NO KEY UPDATE | | X | X | X | |
|
| 1134 | -| FOR UPDATE | X | X | X | X | |
|
| 1135 | - |
|
| 1136 | -### 13.3.3. 页级锁 |
|
| 1137 | - |
|
| 1138 | -除了表级别和行级别的锁以外,页面级别的共享/排他锁被用来控制对共享缓冲池中表页面的读/写。 这些锁在行被抓取或者更新后马上被释放。应用开发者通常不需要关心页级锁,我们在这里提到它们只是为了完整。 |
|
| 1139 | - |
|
| 1140 | -### 13.3.4. 死锁 |
|
| 1141 | - |
|
| 1142 | - |
|
| 1143 | - |
|
| 1144 | -显式锁定的使用可能会增加*死锁*的可能性,死锁是指两个(或多个)事务相互持有对方想要的锁。例如,如果事务 1 在表 A 上获得一个排他锁,同时试图获取一个在表 B 上的排他锁, 而事务 2 已经持有表 B 的排他锁,同时却正在请求表 A 上的一个排他锁,那么两个事务就都不能进行下去。PostgreSQL能够自动检测到死锁情况并且会通过中断其中一个事务从而允许其它事务完成来解决这个问题(具体哪个事务会被中断是很难预测的,而且也不应该依靠这样的预测)。 |
|
| 1145 | - |
|
| 1146 | -要注意死锁也可能会作为行级锁的结果而发生(并且因此,它们即使在没有使用显式锁定的情况下也会发生)。考虑如下情况,两个并发事务在修改一个表。第一个事务执行: |
|
| 1147 | - |
|
| 1148 | -``` |
|
| 1149 | -UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 11111; |
|
| 1150 | -``` |
|
| 1151 | - |
|
| 1152 | -这样就在指定帐号的行上获得了一个行级锁。然后,第二个事务执行: |
|
| 1153 | - |
|
| 1154 | -``` |
|
| 1155 | -UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 22222; |
|
| 1156 | -UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 11111; |
|
| 1157 | -``` |
|
| 1158 | - |
|
| 1159 | -第一个`UPDATE`语句成功地在指定行上获得了一个行级锁,因此它成功更新了该行。 但是第二个`UPDATE`语句发现它试图更新的行已经被锁住了,因此它等待持有该锁的事务结束。事务二现在就在等待事务一结束,然后再继续执行。现在,事务一执行: |
|
| 1160 | - |
|
| 1161 | -``` |
|
| 1162 | -UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 22222; |
|
| 1163 | -``` |
|
| 1164 | - |
|
| 1165 | -事务一试图在指定行上获得一个行级锁,但是它得不到:事务二已经持有了这样的锁。所以它要等待事务二完成。因此,事务一被事务二阻塞,而事务二也被事务一阻塞:一个死锁。 PostgreSQL将检测这样的情况并中断其中一个事务。 |
|
| 1166 | - |
|
| 1167 | -防止死锁的最好方法通常是保证所有使用一个数据库的应用都以一致的顺序在多个对象上获得锁。在上面的例子里,如果两个事务以同样的顺序更新那些行,那么就不会发生死锁。 我们也应该保证一个事务中在一个对象上获得的第一个锁是该对象需要的最严格的锁模式。如果我们无法提前验证这些,那么可以通过重试因死锁而中断的事务来即时处理死锁。 |
|
| 1168 | - |
|
| 1169 | -只要没有检测到死锁情况,寻求一个表级或行级锁的事务将无限等待冲突锁被释放。这意味着一个应用长时间保持事务开启不是什么好事(例如等待用户输入)。 |
|
| 1170 | - |
|
| 1171 | -### 13.3.5. 咨询锁 |
|
| 1172 | - |
|
| 1173 | - |
|
| 1174 | - |
|
| 1175 | -PostgreSQL提供了一种方法创建由应用定义其含义的锁。这种锁被称为*咨询锁*,因为系统并不强迫其使用 — 而是由应用来保证其正确的使用。咨询锁可用于 MVCC 模型不适用的锁定策略。例如,咨询锁的一种常用用法是模拟所谓“平面文件”数据管理系统典型的悲观锁策略。虽然一个存储在表中的标志可以被用于相同目的,但咨询锁更快、可以避免表膨胀并且会由服务器在会话结束时自动清理。 |
|
| 1176 | - |
|
| 1177 | -有两种方法在PostgreSQL中获取一个咨询锁:在会话级别或在事务级别。一旦在会话级别获得了咨询锁,它将被保持直到被显式释放或会话结束。不同于标准锁请求,会话级咨询锁请求不尊重事务语义:在一个后来被回滚的事务中得到的锁在回滚后仍然被保持,并且同样即使调用它的事务后来失败一个解锁也是有效的。一个锁在它所属的进程中可以被获取多次;对于每一个完成的锁请求必须有一个相应的解锁请求,直至锁被真正释放。在另一方面,事务级锁请求的行为更像普通锁请求:在事务结束时会自动释放它们,并且没有显式的解锁操作。这种行为通常比会话级别的行为更方便,因为它使用一个咨询锁的时间更短。对于同一咨询锁标识符的会话级别和事务级别的锁请求按照期望将彼此阻塞。如果一个会话已经持有了一个给定的咨询锁,由它发出的附加请求将总是成功,即使有其他会话在等待该锁;不管现有的锁和新请求是处在会话级别还是事务级别,这种说法都是真的。 |
|
| 1178 | - |
|
| 1179 | -和所有PostgreSQL中的锁一样,当前被任何会话所持有的咨询锁的完整列表可以在[`pg_locks`](https://www.rockdata.net/zh-cn/docs/14/view-pg-locks.html)系统视图中找到。 |
|
| 1180 | - |
|
| 1181 | -咨询锁和普通锁都被存储在一个共享内存池中,它的尺寸由[max_locks_per_transaction](https://www.rockdata.net/zh-cn/docs/14/runtime-config-locks.html#GUC-MAX-LOCKS-PER-TRANSACTION)和[max_connections](https://www.rockdata.net/zh-cn/docs/14/runtime-config-connection.html#GUC-MAX-CONNECTIONS)配置变量定义。 必须当心不要耗尽这些内存,否则服务器将不能再授予任何锁。这对服务器可以授予的咨询锁数量设置了一个上限,根据服务器的配置不同,这个限制通常是数万到数十万。 |
|
| 1182 | - |
|
| 1183 | -在使用咨询锁方法的特定情况下,特别是查询中涉及显式排序和`LIMIT`子句时,由于 SQL 表达式被计算的顺序,必须小心控制锁的获取。例如: |
|
| 1184 | - |
|
| 1185 | -``` |
|
| 1186 | -SELECT pg_advisory_lock(id) FROM foo WHERE id = 12345; -- ok |
|
| 1187 | -SELECT pg_advisory_lock(id) FROM foo WHERE id > 12345 LIMIT 100; -- danger! |
|
| 1188 | -SELECT pg_advisory_lock(q.id) FROM |
|
| 1189 | -( |
|
| 1190 | - SELECT id FROM foo WHERE id > 12345 LIMIT 100 |
|
| 1191 | -) q; -- ok |
|
| 1192 | -``` |
|
| 1193 | - |
|
| 1194 | -在上述查询中,第二种形式是危险的,因为不能保证在锁定函数被执行之前应用`LIMIT`。这可能导致获得某些应用不期望的锁,并因此在会话结束之前无法释放。 从应用的角度来看,这样的锁将被挂起,虽然它们仍然在`pg_locks`中可见。 |
|
| 1195 | - |
|
| 1196 | -提供的操作咨询锁函数在[第 9.27.10 节](https://www.rockdata.net/zh-cn/docs/14/functions-admin.html#FUNCTIONS-ADVISORY-LOCKS)中描述。 |
|
| 1197 | - |
|
| 1198 | - |
|
| 1199 | - |
|
| 1200 | - |
|
| 1201 | - |
|
| 1202 | -## 14. 在 PostgreSQL 中,`UPDATE` 语句的 `SET` 子句中不能使用表别名来引用字段 |
|
| 1203 | - |
|
| 1204 | -在 PostgreSQL 中,`UPDATE` 语句的 `SET` 子句中不能使用表别名来引用字段。例如: |
|
| 1205 | - |
|
| 1206 | -sql |
|
| 1207 | - |
|
| 1208 | -复制 |
|
| 1209 | - |
|
| 1210 | -``` |
|
| 1211 | -UPDATE "tenant_view_ref_model" t |
|
| 1212 | -SET t."view_meta_id" = 'value' -- 错误:不能使用 t."view_meta_id" |
|
| 1213 | -WHERE t.id = '04ifm5h3y4a13'; |
|
| 1214 | -``` |
|
| 1215 | - |
|
| 1216 | -正确的写法应该是直接使用字段名,而不需要表别名: |
|
| 1217 | - |
|
| 1218 | -sql |
|
| 1219 | - |
|
| 1220 | -复制 |
|
| 1221 | - |
|
| 1222 | -``` |
|
| 1223 | -UPDATE "tenant_view_ref_model" |
|
| 1224 | -SET "view_meta_id" = 'value' -- 正确:直接使用字段名 |
|
| 1225 | -WHERE id = '04ifm5h3y4a13'; |
|
| 1226 | -``` |
|
| 1227 | - |
|
| 1228 | -和oracle不同,pgsql的update语法中关联表不使用join ,而是使用from,关联条件不用on,而是写在where中,和条件写在一起。 |
|
| 1229 | - |
|
| 1230 | -使用别名更新时,被更新表的字段不能用别名,如m.code = n.code是不行的。 |
|
| 1231 | - |
|
| 1232 | - |
|
| 1233 | - |
|
| 1234 | -# 15.PostgreSQL 自定义自动类型转换(CAST) |
|
| 1235 | - |
|
| 1236 | -PostgreSQL是一个强类型数据库,因此你输入的变量、常量是什么类型,是强绑定的,例如 |
|
| 1237 | - |
|
| 1238 | -在调用操作符时,需要通过操作符边上的数据类型,选择对应的操作符。 |
|
| 1239 | - |
|
| 1240 | -在调用函数时,需要根据输入的类型,选择对应的函数。 |
|
| 1241 | - |
|
| 1242 | -如果类型不匹配,就会报操作符不存在,或者函数不存在的错误。 |
|
| 1243 | - |
|
| 1244 | -``` |
|
| 1245 | -postgres=# select '1' + '1'; |
|
| 1246 | -ERROR: operator is not unique: unknown + unknown |
|
| 1247 | -LINE 1: select '1' + '1'; |
|
| 1248 | - ^ |
|
| 1249 | -HINT: Could not choose a best candidate operator. You might need to add explicit type casts. |
|
| 1250 | -``` |
|
| 1251 | - |
|
| 1252 | - |
|
| 1253 | - |
|
| 1254 | -那么使用起来是不是很不方便呢? |
|
| 1255 | - |
|
| 1256 | -PostgreSQL开放了类型转换的接口,同时也内置了很多的自动类型转换。来简化操作。 |
|
| 1257 | - |
|
| 1258 | -查看目前已有的类型转换: |
|
| 1259 | - |
|
| 1260 | -``` |
|
| 1261 | -postgres=# \dC+ |
|
| 1262 | - List of casts |
|
| 1263 | - Source type | Target type | Function | Implicit? | Description |
|
| 1264 | ------------------------------+-----------------------------+--------------------+---------------+------------- |
|
| 1265 | - "char" | character | bpchar | in assignment | |
|
| 1266 | - "char" | character varying | text | in assignment | |
|
| 1267 | - "char" | integer | int4 | no | |
|
| 1268 | - "char" | text | text | yes | |
|
| 1269 | - abstime | date | date | in assignment | |
|
| 1270 | - abstime | integer | (binary coercible) | no | |
|
| 1271 | - abstime | time without time zone | time | in assignment | |
|
| 1272 | - |
|
| 1273 | - ................................ |
|
| 1274 | - |
|
| 1275 | - timestamp without time zone | timestamp with time zone | timestamptz | yes | |
|
| 1276 | - timestamp without time zone | timestamp without time zone | timestamp | yes | |
|
| 1277 | - xml | character | (binary coercible) | in assignment | |
|
| 1278 | - xml | character varying | (binary coercible) | in assignment | |
|
| 1279 | - xml | text | (binary coercible) | in assignment | |
|
| 1280 | -(246 rows) |
|
| 1281 | -``` |
|
| 1282 | - |
|
| 1283 | - |
|
| 1284 | - |
|
| 1285 | -注意Implicit列,实际上是pg_cast里面的context转换为可读的内容(e表示no, a表示assignment, 否则表示implicit)。 |
|
| 1286 | - |
|
| 1287 | -``` |
|
| 1288 | -SELECT pg_catalog.format_type(castsource, NULL) AS "Source type", |
|
| 1289 | - pg_catalog.format_type(casttarget, NULL) AS "Target type", |
|
| 1290 | - CASE WHEN castfunc = 0 THEN '(binary coercible)' |
|
| 1291 | - ELSE p.proname |
|
| 1292 | - END as "Function", |
|
| 1293 | - CASE WHEN c.castcontext = 'e' THEN 'no' |
|
| 1294 | - WHEN c.castcontext = 'a' THEN 'in assignment' |
|
| 1295 | - ELSE 'yes' |
|
| 1296 | - END as "Implicit?" |
|
| 1297 | -FROM pg_catalog.pg_cast c LEFT JOIN pg_catalog.pg_proc p |
|
| 1298 | - ON c.castfunc = p.oid |
|
| 1299 | - LEFT JOIN pg_catalog.pg_type ts |
|
| 1300 | - ON c.castsource = ts.oid |
|
| 1301 | - LEFT JOIN pg_catalog.pg_namespace ns |
|
| 1302 | - ON ns.oid = ts.typnamespace |
|
| 1303 | - LEFT JOIN pg_catalog.pg_type tt |
|
| 1304 | - ON c.casttarget = tt.oid |
|
| 1305 | - LEFT JOIN pg_catalog.pg_namespace nt |
|
| 1306 | - ON nt.oid = tt.typnamespace |
|
| 1307 | -WHERE (true AND pg_catalog.pg_type_is_visible(ts.oid) |
|
| 1308 | -) OR (true AND pg_catalog.pg_type_is_visible(tt.oid) |
|
| 1309 | -) |
|
| 1310 | -ORDER BY 1, 2; |
|
| 1311 | -``` |
|
| 1312 | - |
|
| 1313 | - |
|
| 1314 | - |
|
| 1315 | -如果你发现有些类型转换没有内置,怎么办呢?我们可以自定义转换。 |
|
| 1316 | - |
|
| 1317 | -当然你也可以使用这种语法,对类型进行强制转换: |
|
| 1318 | - |
|
| 1319 | -``` |
|
| 1320 | -CAST(x AS typename) |
|
| 1321 | - |
|
| 1322 | - or |
|
| 1323 | - |
|
| 1324 | -x::typename |
|
| 1325 | -``` |
|
| 1326 | - |
|
| 1327 | - |
|
| 1328 | - |
|
| 1329 | -## 如何自定义类型转换(CAST) |
|
| 1330 | - |
|
| 1331 | - |
|
| 1332 | - |
|
| 1333 | -自定义CAST的语法如下: |
|
| 1334 | - |
|
| 1335 | -``` |
|
| 1336 | -CREATE CAST (source_type AS target_type) |
|
| 1337 | - WITH FUNCTION function_name [ (argument_type [, ...]) ] |
|
| 1338 | - [ AS ASSIGNMENT | AS IMPLICIT ] |
|
| 1339 | - |
|
| 1340 | -CREATE CAST (source_type AS target_type) |
|
| 1341 | - WITHOUT FUNCTION |
|
| 1342 | - [ AS ASSIGNMENT | AS IMPLICIT ] |
|
| 1343 | - |
|
| 1344 | -CREATE CAST (source_type AS target_type) |
|
| 1345 | - WITH INOUT |
|
| 1346 | - [ AS ASSIGNMENT | AS IMPLICIT ] |
|
| 1347 | -``` |
|
| 1348 | - |
|
| 1349 | - |
|
| 1350 | - |
|
| 1351 | -解释: |
|
| 1352 | - |
|
| 1353 | -1、WITH FUNCTION,表示转换需要用到什么函数。 |
|
| 1354 | - |
|
| 1355 | -2、WITHOUT FUNCTION,表示被转换的两个类型,在数据库的存储中一致,即物理存储一致。例如text和varchar的物理存储一致。不需要转换函数。 |
|
| 1356 | - |
|
| 1357 | -``` |
|
| 1358 | -Two types can be binary coercible, |
|
| 1359 | -which means that the conversion can be performed “for free” without invoking any function. |
|
| 1360 | - |
|
| 1361 | -This requires that corresponding values use the same internal representation. |
|
| 1362 | - |
|
| 1363 | -For instance, the types text and varchar are binary coercible both ways. |
|
| 1364 | - |
|
| 1365 | -Binary coercibility is not necessarily a symmetric relationship. |
|
| 1366 | - |
|
| 1367 | -For example, the cast from xml to text can be performed for free in the present implementation, |
|
| 1368 | -but the reverse direction requires a function that performs at least a syntax check. |
|
| 1369 | - |
|
| 1370 | -(Two types that are binary coercible both ways are also referred to as binary compatible.) |
|
| 1371 | -``` |
|
| 1372 | - |
|
| 1373 | - |
|
| 1374 | - |
|
| 1375 | -3、WITH INOUT,表示使用内置的IO函数进行转换。每一种类型,都有INPUT 和OUTPUT函数。使用这种方法,好处是不需要重新写转换函数。 |
|
| 1376 | - |
|
| 1377 | -除非有特殊需求,我们建议直接使用IO函数来进行转换。 |
|
| 1378 | - |
|
| 1379 | -``` |
|
| 1380 | - List of functions |
|
| 1381 | - Schema | Name | Result data type | Argument data types | Type |
|
| 1382 | -------------+-----------------+------------------+---------------------+-------- |
|
| 1383 | - pg_catalog | textin | text | cstring | normal |
|
| 1384 | - pg_catalog | textout | cstring | text | normal |
|
| 1385 | - pg_catalog | date_in | date | cstring | normal |
|
| 1386 | - pg_catalog | date_out | cstring | date | normal |
|
| 1387 | -``` |
|
| 1388 | - |
|
| 1389 | - |
|
| 1390 | - |
|
| 1391 | -``` |
|
| 1392 | -You can define a cast as an I/O conversion cast by using the WITH INOUT syntax. |
|
| 1393 | - |
|
| 1394 | -An I/O conversion cast is performed by invoking the output function of the source data type, |
|
| 1395 | -and passing the resulting string to the input function of the target data type. |
|
| 1396 | - |
|
| 1397 | -In many common cases, this feature avoids the need to write a separate cast function for conversion. |
|
| 1398 | - |
|
| 1399 | -An I/O conversion cast acts the same as a regular function-based cast; only the implementation is different. |
|
| 1400 | -``` |
|
| 1401 | - |
|
| 1402 | - |
|
| 1403 | - |
|
| 1404 | -4、AS ASSIGNMENT,表示在赋值时,自动对类型进行转换。例如字段类型为TEXT,输入的类型为INT,那么可以创建一个 cast(int as text) as ASSIGNMENT。 |
|
| 1405 | - |
|
| 1406 | -``` |
|
| 1407 | -If the cast is marked AS ASSIGNMENT then it can be invoked implicitly when assigning a value to a column of the target data type. |
|
| 1408 | - |
|
| 1409 | -For example, supposing that foo.f1 is a column of type text, then: |
|
| 1410 | - |
|
| 1411 | -INSERT INTO foo (f1) VALUES (42); |
|
| 1412 | - |
|
| 1413 | -will be allowed if the cast from type integer to type text is marked AS ASSIGNMENT, |
|
| 1414 | -otherwise not. |
|
| 1415 | - |
|
| 1416 | -(We generally use the term assignment cast to describe this kind of cast.) |
|
| 1417 | -``` |
|
| 1418 | - |
|
| 1419 | - |
|
| 1420 | - |
|
| 1421 | -5、AS IMPLICIT,表示在表达式中,或者在赋值操作中,都对类型进行自动转换。(包含了AS ASSIGNMENT,它只对赋值进行转换) |
|
| 1422 | - |
|
| 1423 | -``` |
|
| 1424 | -If the cast is marked AS IMPLICIT then it can be invoked implicitly in any context, |
|
| 1425 | -whether assignment or internally in an expression. |
|
| 1426 | - |
|
| 1427 | -(We generally use the term implicit cast to describe this kind of cast.) |
|
| 1428 | - |
|
| 1429 | -For example, consider this query: |
|
| 1430 | - |
|
| 1431 | -SELECT 2 + 4.0; |
|
| 1432 | - |
|
| 1433 | -The parser initially marks the constants as being of type integer and numeric respectively. |
|
| 1434 | - |
|
| 1435 | -There is no integer + numeric operator in the system catalogs, but there is a numeric + numeric operator. |
|
| 1436 | - |
|
| 1437 | -The query will therefore succeed if a cast from integer to numeric is available and is marked AS IMPLICIT — |
|
| 1438 | -which in fact it is. |
|
| 1439 | - |
|
| 1440 | -The parser will apply the implicit cast and resolve the query as if it had been written |
|
| 1441 | - |
|
| 1442 | -SELECT CAST ( 2 AS numeric ) + 4.0; |
|
| 1443 | -``` |
|
| 1444 | - |
|
| 1445 | - |
|
| 1446 | - |
|
| 1447 | -6、注意,AS IMPLICIT需要谨慎使用,为什么呢?因为操作符会涉及到多个算子,如果有多个转换,目前数据库并不知道应该选择哪个? |
|
| 1448 | - |
|
| 1449 | -``` |
|
| 1450 | -Now, the catalogs also provide a cast from numeric to integer. |
|
| 1451 | - |
|
| 1452 | -If that cast were marked AS IMPLICIT — (which it is not — ) |
|
| 1453 | - |
|
| 1454 | -then the parser would be faced with choosing between the above interpretation and |
|
| 1455 | -the alternative of casting the numeric constant to integer and applying the integer + integer operator. |
|
| 1456 | - |
|
| 1457 | -Lacking any knowledge of which choice to prefer, it would give up and declare the query ambiguous. |
|
| 1458 | - |
|
| 1459 | -The fact that only one of the two casts is implicit is the way in which we teach the parser to prefer resolution of |
|
| 1460 | -a mixed numeric-and-integer expression as numeric; |
|
| 1461 | - |
|
| 1462 | -there is no built-in knowledge about that. |
|
| 1463 | -``` |
|
| 1464 | - |
|
| 1465 | - |
|
| 1466 | - |
|
| 1467 | -因此,建议谨慎使用AS IMPLICIT。建议使用AS IMPLICIT的CAST应该是非失真转换转换,例如从INT转换为TEXT,或者int转换为numeric。 |
|
| 1468 | - |
|
| 1469 | -而失真转换,不建议使用as implicit,例如numeric转换为int。 |
|
| 1470 | - |
|
| 1471 | -``` |
|
| 1472 | -It is wise to be conservative about marking casts as implicit. |
|
| 1473 | - |
|
| 1474 | -An overabundance of implicit casting paths can cause PostgreSQL to choose surprising interpretations of commands, |
|
| 1475 | -or to be unable to resolve commands at all because there are multiple possible interpretations. |
|
| 1476 | - |
|
| 1477 | -A good rule of thumb is to make a cast implicitly invokable only for information-preserving |
|
| 1478 | -transformations between types in the same general type category. |
|
| 1479 | - |
|
| 1480 | -For example, the cast from int2 to int4 can reasonably be implicit, |
|
| 1481 | -but the cast from float8 to int4 should probably be assignment-only. |
|
| 1482 | - |
|
| 1483 | -Cross-type-category casts, such as text to int4, are best made explicit-only. |
|
| 1484 | -``` |
|
| 1485 | - |
|
| 1486 | - |
|
| 1487 | - |
|
| 1488 | -## 注意事项 + 例子 |
|
| 1489 | - |
|
| 1490 | - |
|
| 1491 | - |
|
| 1492 | -不能嵌套转换。例子 |
|
| 1493 | - |
|
| 1494 | -1、将text转换为date |
|
| 1495 | - |
|
| 1496 | -错误方法 |
|
| 1497 | - |
|
| 1498 | -``` |
|
| 1499 | -create or replace function text_to_date(text) returns date as $$ |
|
| 1500 | - select cast($1 as date); |
|
| 1501 | -$$ language sql strict; |
|
| 1502 | - |
|
| 1503 | -create cast (text as date) with function text_to_date(text) as implicit; |
|
| 1504 | -``` |
|
| 1505 | - |
|
| 1506 | - |
|
| 1507 | - |
|
| 1508 | -嵌套转换后出现死循环 |
|
| 1509 | - |
|
| 1510 | -``` |
|
| 1511 | -postgres=# select text '2017-01-01' + 1; |
|
| 1512 | -ERROR: stack depth limit exceeded |
|
| 1513 | -HINT: Increase the configuration parameter "max_stack_depth" (currently 2048kB), after ensuring the platform's stack depth limit is adequate. |
|
| 1514 | -CONTEXT: SQL function "text_to_date" during startup |
|
| 1515 | -SQL function "text_to_date" statement 1 |
|
| 1516 | -SQL function "text_to_date" statement 1 |
|
| 1517 | -SQL function "text_to_date" statement 1 |
|
| 1518 | -...... |
|
| 1519 | -``` |
|
| 1520 | - |
|
| 1521 | - |
|
| 1522 | - |
|
| 1523 | -正确方法 |
|
| 1524 | - |
|
| 1525 | -``` |
|
| 1526 | -create or replace function text_to_date(text) returns date as $$ |
|
| 1527 | - select to_date($1,'yyyy-mm-dd'); |
|
| 1528 | -$$ language sql strict; |
|
| 1529 | - |
|
| 1530 | -create cast (text as date) with function text_to_date(text) as implicit; |
|
| 1531 | -``` |
|
| 1532 | - |
|
| 1533 | - |
|
| 1534 | - |
|
| 1535 | -``` |
|
| 1536 | -postgres=# select text '2017-01-01' + 1; |
|
| 1537 | - ?column? |
|
| 1538 | ------------- |
|
| 1539 | - 2017-01-02 |
|
| 1540 | -(1 row) |
|
| 1541 | -``` |
|
| 1542 | - |
|
| 1543 | - |
|
| 1544 | - |
|
| 1545 | -我们还可以直接使用IO函数来转换: |
|
| 1546 | - |
|
| 1547 | -``` |
|
| 1548 | -postgres=# create cast (text as date) with inout as implicit; |
|
| 1549 | -CREATE CAST |
|
| 1550 | - |
|
| 1551 | -postgres=# select text '2017-01-01' + 1; |
|
| 1552 | - ?column? |
|
| 1553 | ------------- |
|
| 1554 | - 2017-01-02 |
|
| 1555 | -(1 row) |
|
| 1556 | -``` |
|
| 1557 | - |
|
| 1558 | - |
|
| 1559 | - |
|
| 1560 | -## 参考 |
|
| 1561 | - |
|
| 1562 | - |
|
| 1563 | - |
|
| 1564 | -https://www.postgresql.org/docs/10/static/sql-createcast.html |
|
| 1565 | - |
|
| 1566 | -[《PostgreSQL 整型int与布尔boolean的自动转换设置》](https://github.com/digoal/blog/blob/master/201801/20180131_01.md) |
|
| 1567 | - |
|
| 1568 | - |
|
| 1569 | - |
|
| 1570 | - |
|
| 1571 | - |
|
| 1572 | -# 16 不兼容项 |
|
| 1573 | - |
|
| 1574 | - |
|
| 1575 | - |
|
| 1576 | -```json |
|
| 1577 | -{ |
|
| 1578 | - "id": "guid", |
|
| 1579 | - "jsonrpc": "2.0", |
|
| 1580 | - "method": "service", |
|
| 1581 | - "params": { |
|
| 1582 | - "args": { |
|
| 1583 | - "ids": [ |
|
| 1584 | - "rbac_test_2" |
|
| 1585 | - ], |
|
| 1586 | - "values": { |
|
| 1587 | - "a": "3", |
|
| 1588 | - "lastName": "1", |
|
| 1589 | - "b": 21, |
|
| 1590 | - "c": 7.2, |
|
| 1591 | - "d": "2023-01-16", |
|
| 1592 | - "e": "abc", |
|
| 1593 | - "html": "1", |
|
| 1594 | - "testUser": "rbac_role_admin", |
|
| 1595 | - "d2": "2023-01-20 09:10:10", |
|
| 1596 | - "id": "rbac_test_2" |
|
| 1597 | - }, |
|
| 1598 | - "useDisplayForModel": true |
|
| 1599 | - }, |
|
| 1600 | - "context": { |
|
| 1601 | - "uid": "", |
|
| 1602 | - "timeZone": "UTC+8", |
|
| 1603 | - "lang": "zh-CN" |
|
| 1604 | - }, |
|
| 1605 | - "model": "TestTest1", |
|
| 1606 | - "tag": "master", |
|
| 1607 | - "service": "newSdkApp.TestTest1.TestTest_form.form:master#update", |
|
| 1608 | - "app": "newSdkApp" |
|
| 1609 | - } |
|
| 1610 | -} |
|
| 1611 | -``` |
|
| 1612 | - |
|
| 1613 | -aused by: org.postgresql.util.PSQLException: 错误: 当前事务被终止, 事务块结束之前的查询被忽略 |
|
| 1614 | - |
|
| 1615 | - at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2674) |
|
| 1616 | - |
|
| 1617 | - at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2364) |
|
| 1618 | - |
|
| 1619 | - at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:354) |
|
| 1620 | - |
|
| 1621 | - at org.postgresql.jdbc.PgStatement.executeInternal(PgStatement.java:484) |
|
| 1622 | - |
|
| 1623 | - at org.postgresql.jdbc.PgStatement.execute(PgStatement.java:404) |
|
| 1624 | - |
|
| 1625 | - at org.postgresql.jdbc.PgPreparedStatement.executeWithFlags(PgPreparedStatement.java:162) |
|
| 1626 | - |
|
| 1627 | - at org.postgresql.jdbc.PgPreparedStatement.execute(PgPreparedStatement.java:151) |
|
| 1628 | - |
|
| 1629 | - at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3461) |
|
| 1630 | - |
|
| 1631 | - at com.alibaba.druid.filter.FilterEventAdapter.preparedStatement_execute(FilterEventAdapter.java:440) |
|
| 1632 | - |
|
| 1633 | - at com.alibaba.druid.filter.FilterChainImpl.preparedStatement_execute(FilterChainImpl.java:3459) |
|
| 1634 | - |
|
| 1635 | - at com.alibaba.druid.proxy.jdbc.PreparedStatementProxyImpl.execute(PreparedStatementProxyImpl.java:167) |
|
| 1636 | - |
|
| 1637 | - at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:497) |
|
| 1638 | - |
|
| 1639 | - at com.sie.snest.engine.db.relationdb.RelationDBAccessor.doExecute(RelationDBAccessor.java:614) |
|
| 1640 | - |
|
| 1641 | - ... 82 common frames omitted |
|
| 1642 | - |
|
| 1643 | -Caused by: org.postgresql.util.PSQLException: 错误: 字段 "age" 的类型为 integer, 但表达式的类型为 character varying |
|
| 1644 | - |
|
| 1645 | - 建议:你需要重写或转换表达式 |
|
| 1646 | - |
|
| 1647 | - 位置:245 |
|
| 1648 | - |
|
| 1649 | - |
|
| 1650 | - |
|
| 1651 | - |
|
| 1652 | - |
|
| 1653 | -## 16.1 boolean值问题 |
|
| 1654 | - |
|
| 1655 | -pg支持boolean,但是我们引擎是使用char(1)代替boolean |
|
| 1656 | - |
|
| 1657 | -## 16.2 索引问题,索引 |
|
| 1658 | - |
|
| 1659 | -2. 在 PostgreSQL 中,索引名称(Index Name)的最大长度受限于标识符(Identifier)的最大长度。根据 PostgreSQL 的官方文档,标识符的最大长度为 **63 字节**。 |
|
| 1660 | - |
|
| 1661 | - ------ |
|
| 1662 | - |
|
| 1663 | - ## 1. **标识符的最大长度** |
|
| 1664 | - |
|
| 1665 | - - PostgreSQL 中的标识符(如表名、列名、索引名等)最大长度为 **63 字节**。 |
|
| 1666 | - - 如果标识符的长度超过 63 字节,PostgreSQL 会自动截断到 63 字节,并发出警告。 |
|
| 1667 | - |
|
| 1668 | - |
|
| 1669 | - |
|
| 1670 | -在 PostgreSQL 中,索引名称(Index Name)的命名规则和限制与其他数据库对象(如表、列、约束等)类似。以下是 PostgreSQL 索引命名的详细限制和最佳实践: |
|
| 1671 | - |
|
| 1672 | ------- |
|
| 1673 | - |
|
| 1674 | -## 1. **索引命名的基本规则** |
|
| 1675 | - |
|
| 1676 | -- **长度限制**:索引名称的最大长度为 **63 字节**。如果名称超过 63 字节,PostgreSQL 会自动截断并发出警告。 |
|
| 1677 | -- **字符集**:索引名称可以包含字母、数字、下划线(`_`)和其他特殊字符(如 `$`),但通常建议使用字母、数字和下划线。 |
|
| 1678 | -- **大小写敏感性**:索引名称是大小写不敏感的,但 PostgreSQL 会将名称转换为小写存储。如果需要保留大小写,可以使用双引号(`"`)包裹名称。 |
|
| 1679 | -- **唯一性**:在同一个 schema 中,索引名称必须是唯一的。 |
|
| 1680 | - |
|
| 1681 | ------- |
|
| 1682 | - |
|
| 1683 | -## 2. **索引命名的限制** |
|
| 1684 | - |
|
| 1685 | -### (1) **长度限制** |
|
| 1686 | - |
|
| 1687 | -索引名称的最大长度为 63 字节。如果名称超过 63 字节,PostgreSQL 会截断名称并发出警告。 |
|
| 1688 | - |
|
| 1689 | -例如: |
|
| 1690 | - |
|
| 1691 | -sql |
|
| 1692 | - |
|
| 1693 | -复制 |
|
| 1694 | - |
|
| 1695 | -``` |
|
| 1696 | -CREATE INDEX this_is_a_very_long_index_name_that_exceeds_the_maximum_length_of_sixty_three_bytes ON my_table(my_column); |
|
| 1697 | -``` |
|
| 1698 | - |
|
| 1699 | -PostgreSQL 会将其截断为: |
|
| 1700 | - |
|
| 1701 | -复制 |
|
| 1702 | - |
|
| 1703 | -``` |
|
| 1704 | -this_is_a_very_long_index_name_that_exceeds_the_maximum_length_of_sixty_three |
|
| 1705 | -``` |
|
| 1706 | - |
|
| 1707 | -### (2) **大小写敏感性** |
|
| 1708 | - |
|
| 1709 | -默认情况下,索引名称会被转换为小写存储。如果需要保留大小写,可以使用双引号包裹名称。 |
|
| 1710 | - |
|
| 1711 | -例如: |
|
| 1712 | - |
|
| 1713 | -sql |
|
| 1714 | - |
|
| 1715 | -复制 |
|
| 1716 | - |
|
| 1717 | -``` |
|
| 1718 | -CREATE INDEX "MyIndex" ON my_table(my_column); |
|
| 1719 | -``` |
|
| 1720 | - |
|
| 1721 | -此时,索引名称会保留为 `MyIndex`。 |
|
| 1722 | - |
|
| 1723 | -### (3) **特殊字符** |
|
| 1724 | - |
|
| 1725 | -索引名称可以包含特殊字符(如 `$`、`#` 等),但通常不建议使用,因为可能会导致兼容性问题。 |
|
| 1726 | - |
|
| 1727 | -例如: |
|
| 1728 | - |
|
| 1729 | -sql |
|
| 1730 | - |
|
| 1731 | -复制 |
|
| 1732 | - |
|
| 1733 | -``` |
|
| 1734 | -CREATE INDEX "my_index$1" ON my_table(my_column); |
|
| 1735 | -``` |
|
| 1736 | - |
|
| 1737 | -### (4) **唯一性** |
|
| 1738 | - |
|
| 1739 | -在同一个 schema 中,索引名称必须是唯一的。如果尝试创建同名的索引,PostgreSQL 会抛出错误。 |
|
| 1740 | - |
|
| 1741 | -例如: |
|
| 1742 | - |
|
| 1743 | -sql |
|
| 1744 | - |
|
| 1745 | -复制 |
|
| 1746 | - |
|
| 1747 | -``` |
|
| 1748 | -CREATE INDEX my_index ON my_table(my_column); |
|
| 1749 | -CREATE INDEX my_index ON my_table(another_column); -- 错误:索引名称冲突 |
|
| 1750 | -``` |
|
| 1751 | - |
|
| 1752 | ------- |
|
| 1753 | - |
|
| 1754 | -## 3. **索引命名的最佳实践** |
|
| 1755 | - |
|
| 1756 | -### (1) **使用有意义的名称** |
|
| 1757 | - |
|
| 1758 | -索引名称应反映其用途,例如: |
|
| 1759 | - |
|
| 1760 | -- `idx_table_column`:表示在 `table` 表的 `column` 列上创建的索引。 |
|
| 1761 | -- `uk_table_column`:表示在 `table` 表的 `column` 列上创建的唯一约束索引。 |
|
| 1762 | - |
|
| 1763 | -### (2) **避免使用保留字** |
|
| 1764 | - |
|
| 1765 | -避免使用 PostgreSQL 的保留字(如 `SELECT`、`INSERT` 等)作为索引名称。 |
|
| 1766 | - |
|
| 1767 | -### (3) **使用一致的命名规则** |
|
| 1768 | - |
|
| 1769 | -为索引名称定义一致的命名规则,例如: |
|
| 1770 | - |
|
| 1771 | -- 前缀:使用 `idx_` 表示普通索引,`uk_` 表示唯一索引,`pk_` 表示主键索引。 |
|
| 1772 | -- 表名和列名:在索引名称中包含表名和列名。 |
|
| 1773 | - |
|
| 1774 | -例如: |
|
| 1775 | - |
|
| 1776 | -sql |
|
| 1777 | - |
|
| 1778 | -复制 |
|
| 1779 | - |
|
| 1780 | -``` |
|
| 1781 | -CREATE INDEX idx_users_email ON users(email); |
|
| 1782 | -CREATE UNIQUE INDEX uk_users_username ON users(username); |
|
| 1783 | -``` |
|
| 1784 | - |
|
| 1785 | -### (4) **避免过长的名称** |
|
| 1786 | - |
|
| 1787 | -尽量保持索引名称简洁,避免超过 63 字节的限制。 |
|
| 1788 | - |
|
| 1789 | ------- |
|
| 1790 | - |
|
| 1791 | -## 4. **修改索引名称** |
|
| 1792 | - |
|
| 1793 | -如果索引名称不符合要求,可以使用 `ALTER INDEX` 修改索引名称。 |
|
| 1794 | - |
|
| 1795 | -例如: |
|
| 1796 | - |
|
| 1797 | -sql |
|
| 1798 | - |
|
| 1799 | -复制 |
|
| 1800 | - |
|
| 1801 | -``` |
|
| 1802 | -ALTER INDEX old_index_name RENAME TO new_index_name; |
|
| 1803 | -``` |
|
| 1804 | - |
|
| 1805 | ------- |
|
| 1806 | - |
|
| 1807 | -## 5. **查看索引名称** |
|
| 1808 | - |
|
| 1809 | -可以通过以下 SQL 查询当前数据库中的所有索引及其名称: |
|
| 1810 | - |
|
| 1811 | -sql |
|
| 1812 | - |
|
| 1813 | -复制 |
|
| 1814 | - |
|
| 1815 | -``` |
|
| 1816 | -SELECT schemaname, tablename, indexname |
|
| 1817 | -FROM pg_indexes |
|
| 1818 | -WHERE schemaname NOT LIKE 'pg_%' -- 排除系统 schema |
|
| 1819 | -ORDER BY schemaname, tablename, indexname; |
|
| 1820 | -``` |
|
| 1821 | - |
|
| 1822 | ------- |
|
| 1823 | - |
|
| 1824 | -## 6. **总结** |
|
| 1825 | - |
|
| 1826 | -- PostgreSQL 索引名称的最大长度为 **63 字节**。 |
|
| 1827 | -- 索引名称在同一个 schema 中必须是唯一的。 |
|
| 1828 | -- 默认情况下,索引名称会被转换为小写存储,可以使用双引号保留大小写。 |
|
| 1829 | -- 建议使用有意义的命名规则,并避免使用特殊字符和保留字。 |
|
| 1830 | - |
|
| 1831 | -通过遵循这些规则和最佳实践,可以确保索引名称的可读性和一致性。 |
|
| 1832 | - |
|
| 1833 | - |
|
| 1834 | - |
|
| 1835 | -## 16.3. 事物问题 |
|
| 1836 | - |
|
| 1837 | -- PostgreSQL支持Transactional DDL |
|
| 1838 | - |
|
| 1839 | -- Transactional DDL |
|
| 1840 | - |
|
| 1841 | - PostgreSQL supports transactional DDL ([Data Definition Language](https://en.wikipedia.org/wiki/Data_definition_language)) operations, such as `CREATE`, `ALTER`, and `DROP` statements. This means that schema-altering operations can be included within a transaction block and rolled back if required. In MySQL, DDL statements [are typically not transactional](https://dev.mysql.com/doc/refman/8.0/en/cannot-roll-back.html). Thus, when an error occurs during a schema-altering operation, it cannot be rolled back. |
|
| 1842 | - |
|
| 1843 | - https://wiki.postgresql.org/wiki/Transactional_DDL_in_PostgreSQL:_A_Competitive_Analysis |
|
| 1844 | - |
|
| 1845 | - |
|
| 1846 | - |
|
| 1847 | - # PostgreSQL支持Transactional DDL |
|
| 1848 | - |
|
| 1849 | - [PostgreSQL运维技术](https://www.modb.pro/u/431686)2022-08-20 |
|
| 1850 | - |
|
| 1851 | - 1228 |
|
| 1852 | - |
|
| 1853 | - ## 什么是Transactional DDL? |
|
| 1854 | - |
|
| 1855 | - Transactional(事务)在关系型数据库是指一组SQL语句,要么提交,要么全部回滚。事务中包含的语句通常是DML语句,如INSERT、UPDATE、DELETE等。但是对于DDL语句呢?是否可以在事务中包含诸如CREATE、ALTER、DROP等DDL命令? |
|
| 1856 | - |
|
| 1857 | - 所谓Transactional DDL就是我们可以把ddl放到事务中,做到事务中的ddl语句要么全部提交,要么全部**回滚**。 |
|
| 1858 | - |
|
| 1859 | - ## PG是否支持Transactional DDL? |
|
| 1860 | - |
|
| 1861 | - 看个pg的例子 |
|
| 1862 | - |
|
| 1863 | - ``` |
|
| 1864 | - postgres=# begin; |
|
| 1865 | - BEGIN |
|
| 1866 | - postgres=*# create table a_test(id int); |
|
| 1867 | - CREATE TABLE |
|
| 1868 | - postgres=*# insert into a_test values(1); |
|
| 1869 | - INSERT 0 1 |
|
| 1870 | - postgres=*# rollback; |
|
| 1871 | - ROLLBACK |
|
| 1872 | - postgres=# select * from a_test; |
|
| 1873 | - ERROR: relation "a_test" does not exist |
|
| 1874 | - LINE 1: select * from a_test; |
|
| 1875 | - ^ |
|
| 1876 | - postgres=# |
|
| 1877 | - ``` |
|
| 1878 | - |
|
| 1879 | - 可见,在postgresql中,是支持transactional ddl的,在上例中,create table语句被回滚掉了。 |
|
| 1880 | - |
|
| 1881 | - 并不是所有数据库都支持Transactional ddl,比如mysql。 |
|
| 1882 | - |
|
| 1883 | - 看个mysql的例子: |
|
| 1884 | - |
|
| 1885 | - ``` |
|
| 1886 | - mysql> begin; |
|
| 1887 | - Query OK, 0 rows affected (0.00 sec) |
|
| 1888 | - |
|
| 1889 | - mysql> create table a_test (id int); |
|
| 1890 | - Query OK, 0 rows affected (0.04 sec) |
|
| 1891 | - |
|
| 1892 | - mysql> insert into a_test values(1); |
|
| 1893 | - Query OK, 1 row affected (0.01 sec) |
|
| 1894 | - |
|
| 1895 | - mysql> rollback; |
|
| 1896 | - Query OK, 0 rows affected (0.00 sec) |
|
| 1897 | - |
|
| 1898 | - mysql> select * from a_test; |
|
| 1899 | - +------+ |
|
| 1900 | - | id | |
|
| 1901 | - +------+ |
|
| 1902 | - | 1 | |
|
| 1903 | - +------+ |
|
| 1904 | - 1 row in set (0.00 sec) |
|
| 1905 | - ``` |
|
| 1906 | - |
|
| 1907 | - 可以看到mysql这个例子里,不仅create语句没有回滚掉,insert语句也没有回滚掉。这是因为:在mysql中,当执行ddl语句时,会隐式地将当前会话的事务进行一次commit操作。 所以我们应该**严格地将DDL和DML完全分开**,不能混合在一起执行。 |
|
| 1908 | - |
|
| 1909 | - ## 一些特例 |
|
| 1910 | - |
|
| 1911 | - 需要注意的是在pg中并不是所有的ddl都支持Transactional ddl。比如CREATE INDEX CONCURRENTLY、CREATE DATABAE 、CREATE TABLESPACE等等。 |
|
| 1912 | - |
|
| 1913 | - ``` |
|
| 1914 | - postgres=# begin |
|
| 1915 | - postgres-# ; |
|
| 1916 | - BEGIN |
|
| 1917 | - postgres=*# CREATE INDEX CONCURRENTLY idx_id ON a_test (id); |
|
| 1918 | - ERROR: CREATE INDEX CONCURRENTLY cannot run inside a transaction block |
|
| 1919 | - ``` |
|
| 1920 | - |
|
| 1921 | - ## Transactional DDL的好处 |
|
| 1922 | - |
|
| 1923 | - 在进行一些模式升级等复杂工作时,可以利用此功能保护数据库。我们可以将所有更改都放入事务块中,确保它们都以原子方式应用,或者根本不应用。这大大降低了数据库因模式更改中的输入错误或其他此类错误而损坏数据库的可能性。 |
|
| 1924 | - |
|
| 1925 | - ## 总结 |
|
| 1926 | - |
|
| 1927 | - transactional ddl是指可以把ddl放到事务中,做到事务中的ddl语句要么全部提交,要么全部回滚。 |
|
| 1928 | - |
|
| 1929 | - PG大部分ddl都支持Transactional ddl,除了一些CREATE INDEX CONCURRENTLY、CREATE DATABAE 、CREATE TABLESPACE等语句。 |
|
| 1930 | - |
|
| 1931 | - |
|
| 1932 | - |
|
| 1933 | - |
|
| 1934 | - |
|
| 1935 | - 参考: |
|
| 1936 | - |
|
| 1937 | - https://wiki.postgresql.org/wiki/Transactional_DDL_in_PostgreSQL:_A_Competitive_Analysis |
|
| 1938 | - |
|
| 1939 | - https://www.cybertec-postgresql.com/en/transactional-ddls/ |
|
| 1940 | - |
|
| 1941 | - |
|
| 1942 | - |
|
| 1943 | -## 16.4 数据类型转换 |
|
| 1944 | - |
|
| 1945 | -- PostgreSQL必须显示的进行数据类型转换 |
|
| 1946 | - |
|
| 1947 | -- 0 1 字符串,字符串不会显示的转换成boolean,不会显示的转换成数字 |
|
| 1948 | - |
|
| 1949 | -- caused by: org.postgresql.util.PSQLException: 错误: 字段 "age" 的类型为 integer, 但表达式的类型为 character varying |
|
| 1950 | - |
|
| 1951 | - 建议:你需要重写或转换表达式 |
|
| 1952 | - |
|
| 1953 | - 位置:245 |
|
| 1954 | - |
|
| 1955 | - |
|
| 1956 | - |
|
| 1957 | - |
|
| ... | ... | \ No newline at end of file |
| 0 | +- [使用 Golang 连接到 PostgreSQL](https://www.rockdata.net/zh-cn/tutorial/golang-setup/) – 向您介绍如何使用 Go 编程语言与 PostgreSQL 数据库进行交互。 |
|
| ... | ... | \ No newline at end of file |